大厂实践 - 美团:美团外卖搜索基于Elasticsearch的优化实践
大厂实践 - 美团:美团外卖搜索基于Elasticsearch的优化实践
美团外卖搜索工程团队在Elasticsearch的优化实践中,基于Location-Based Service(LBS)业务场景对Elasticsearch的查询性能进行优化。该优化基于Run-Length Encoding(RLE)设计了一款高效的倒排索引结构,使检索耗时(TP99)降低了84%。本文从问题分析、技术选型、优化方案等方面进行阐述,并给出最终灰度验证的结论。
1. 前言
最近十年,Elasticsearch 已经成为了最受欢迎的开源检索引擎,其作为离线数仓、近线检索、B端检索的经典基建,已沉淀了大量的实践案例及优化总结。然而在高并发、高可用、大数据量的 C 端场景,目前可参考的资料并不多。因此,我们希望通过分享在外卖搜索场景下的优化实践,能为大家提供 Elasticsearch 优化思路上的一些借鉴。
美团在外卖搜索业务场景中大规模地使用了 Elasticsearch 作为底层检索引擎。其在过去几年很好地支持了外卖每天十亿以上的检索流量。然而随着供给与数据量的急剧增长,业务检索耗时与 CPU 负载也随之上涨。通过分析我们发现,当前检索的性能热点主要集中在倒排链的检索与合并流程中。针对这个问题,我们基于 Run-length Encoding(RLE)[1] 技术设计实现了一套高效的倒排索引,使倒排链合并时间(TP99)降低了 96%。我们将这一索引能力开发成了一款通用插件集成到 Elasticsearch 中,使得 Elasticsearch 的检索链路时延(TP99)降低了 84%。
2. 背景
当前,外卖搜索业务检索引擎主要为 Elasticsearch,其业务特点是具有较强的 Location Based Service(LBS) 依赖,即用户所能点餐的商家,是由商家配送范围决定的。对于每一个商家的配送范围,大多采用多组电子围栏进行配送距离的圈定,一个商家存在多组电子围栏,并且随着业务的变化会动态选择不同的配送范围,电子围栏示意图如下:
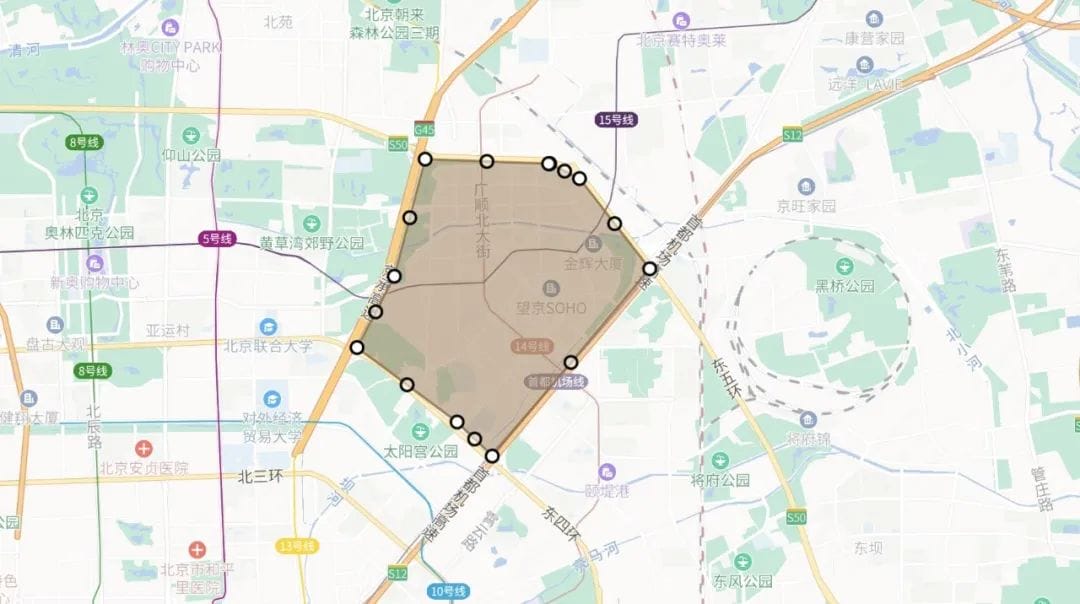
考虑到商家配送区域动态变更带来的问题,我们没有使用 Geo Polygon[2] 的方式进行检索,而是通过上游一组 R-tree 服务判定可配送的商家列表来进行外卖搜索。因此,LBS 场景下的一次商品检索,可以转化为如下的一次 Elasticsearch 搜索请求:
POST food/_search
{
"query": {
"bool": {
"must":{
"term": { "spu_name": { "value": "烤鸭"} }
//...
},
"filter":{
"terms": {
"wm_poi_id": [1,3,18,27,28,29,...,37465542] // 上万
}
}
}
}
//...
}
对于一个通用的检索引擎而言,Term 检索非常高效,一次 Term 检索耗时不到 0.001 ms。因此在早期时,这一套架构和检索 DSL 可以很好地支持美团的搜索业务——耗时和资源开销尚在接受范围内。然而随着数据和供给的增长,一些供给丰富区域的附近可配送门店可以达到 20000~30000 家,这导致性能与资源问题逐渐凸显。这种万级别的 Terms 检索的性能与耗时已然无法忽略,仅仅这一句检索就需要 5~10 ms。
3. 挑战及问题
由于 Elasticsearch 在设计上针对海量的索引数据进行优化,在过去的 10 年间,逐步去除了内存支持索引的功能(例如 RAMDirectory 的删除)。为了能够实现超大规模候选集的检索,Elasticsearch/Lucene 对 Term 倒排链的查询流程设计了一套内存与磁盘共同处理的方案。
一次 Terms 检索的流程分为两步:分别检索单个 Term 的倒排链,多个 Term 的倒排链进行合并。
3.1 倒排链查询流程
- 从内存中的 Term Index 中获取该 Term 所在的 Block 在磁盘上的位置。
- 从磁盘中将该 Block 的 TermDictionary 读取进内存。
- 对倒排链存储格式的进行 Decode,生成可用于合并的倒排链。
可以看到,这一查询流程非常复杂且耗时,且各个阶段的复杂度都不容忽视。所有的 Term 在索引中有序存储,通过二分查找找到目标 Term。这个有序的 Term 列表就是 TermDictionary ,二分查找 Term 的时间复杂度为 O(logN) ,其中 N 是 Term 的总数量 。Lucene 采用 Finite State Transducer[3](FST)对 TermDictionary 进行编码构建 Term Index。FST 可对 Term 的公共前缀、公共后缀进行拆分保存,大大压缩了 TermDictionary 的体积,提高了内存效率,FST 的检索速度是 O(len(term)),其对于 M 个 Term 的检索复杂度为 O(M * len(term))。
3.2 倒排链合并流程
在经过上述的查询,检索出所有目标 Term 的 Posting List 后,需要对这些 Posting List 求并集(OR 操作)。在 Lucene 的开源实现中,其采用 Bitset 作为倒排链合并的容器,然后遍历所有倒排链中的每一个文档,将其加入 DocIdSet 中。
伪代码如下:
Input: termsEnum: 倒排表;termIterator:候选的term
Output: docIdSet : final docs set
for term in termIterator:
if termsEnum.seekExact(term) != null:
docs = read_disk() // 磁盘读取
docs = decode(docs) // 倒排链的decode流程
for doc in docs:
docIdSet.or(doc) //代码实现为DocIdSetBuilder.add。
end for
docIdSet.build()//合并,排序,最终生成DocIdSetBuilder,对应火焰图最后一段。
假设我们有 M 个 Term,每个 Term 对应倒排链的平均长度为 K,那么合并这 M 个倒排链的时间复杂度为:O(K * M + log(K * M))。可以看出倒排链合并的时间复杂度与 Terms 的数量 M 呈线性相关。在我们的场景下,假设一个商家平均有一千个商品,一次搜索请求需要对一万个商家进行检索,那么最终需要合并一千万个商品,即循环执行一千万次,导致这一问题被放大至无法被忽略的程度。
我们也针对当前的系统做了大量的调研及分析,通过美团内部的 JVM Profile 系统得到 CPU 的火焰图,可以看到这一流程在 CPU 热点图中的反映也是如此:无论是查询倒排链、还是读取、合并倒排链都相当消耗资源,并且可以预见的是,在供给越来越多的情况下,这三个阶段的耗时还会持续增长。
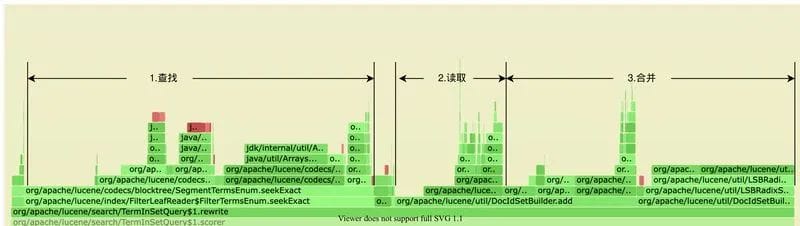
可以明确,我们需要针对倒排链查询、倒排链合并这两个问题予以优化。
4. 技术探索与实践
4.1 倒排链查询优化
通常情况下,使用 FST 作为 Term 检索的数据结构,可以在内存开销和计算开销上取得一个很好的平衡,同时支持前缀检索、正则检索等多种多样的检索 Query,然而在我们的场景之下,FST 带来的计算开销无法被忽视。
考虑到在外卖搜索场景有以下几个特性:
- Term 的数据类型为 long 类型。
- 无范围检索,均为完全匹配。
- 无前缀匹配、模糊查找的需求,不需要使用前缀树相关的特性。
- 候选数量可控,每个商家的商品数量较多,即 Term 规模可预期,内存可以承载这个数量级的数据。
因此在我们的应用场景中使用空间换取时间是值得的。
对于 Term 查询的热点:可替换 FST 的实现以减少 CPU 开销,常见的查找数据结构中,哈希表有 O(1) 的查询复杂度,将 Term 查找转变为对哈希表的一次查询。
对于哈希表的选取,我们主要选择了常见的 HashMap 和 LongObjectHashMap。
我们主要对比了 FST、HashMap 和 LongObjectHashMap(哈希表的一种高性能实现)的空间和时间效率。
- 在内存占用上:FST 的内存效率极佳。而 HashMap/LongObjectHashMap 都有明显的劣势;
- 在查询时间上:FST 的查询复杂度在 O (len(term)),而 Hash/LongObjectHashMap 有着 O(1) 的查询性能;
注:检索类型虽然为 Long,但是我们将底层存储格式进行了调整,没有使用开源的 BKD Tree 实现,使用 FST 结构,仅与 FST 进行对比。BKD Tree 在大批量整数 terms 的场景下劣势更为明显。
我们使用十万个 <Long, Long>的键值对来构造数据,对其空间及性能进行了对比,结果如下:

可以看到, 在内存占用上 FST 要远优于 LongObjectHashMap 和 HashMap。而在查询速度上 LongObjectHashMap 最优。
我们最终选择了 LongObjectHashMap 作为倒排链查询的数据结构。
4.2 倒排链合并
基于上述问题,我们需要解决两个明显的 CPU 热点问题:倒排链读取 & 倒排链合并。我们需要选择合适的数据结构缓存倒排链,不再执行磁盘 /page cache 的 IO。数据结构需要必须满足以下条件:
- 支持批量 Merge,减少倒排链 Merge 耗时。
- 内存占用少,需要处理千万数量级的倒排链。
在给出具体的解决方案之前,先介绍一下 Lucene 对于倒排合并的原生实现、RoaringBitMap、Index Sorting。
4.2.1 原生实现
Lucene在不同场景上使用了不同的倒排格式,提高整体的效率(空间/时间),通过火焰图可以发现,在我们的场景上,TermInSetQuery 的倒排合并逻辑开销最大。
TermInSetQuery 的倒排链合并操作分为两个步骤:倒排链读取和合并。
- 倒排链读取:
Lucene 倒排链压缩存储在索引文件中,倒排链读取需要实时解析,其对外暴露的 API 为迭代器结构。
- 倒排链合并:
倒排链合并主要由 DocIdSetBuilder 合并生成倒排链,先使用稀疏结构存储 Doc ID,当 Doc ID 个数超过一定阈值时,升级到稠密结构(FixedBitSet)存储,实现方式如下(对应代码 IntArrayDocIdSet/BitDocIdSet):
- 稀疏数据:存储采用
List<int[]> array方式存储 Doc ID,最终经过 Merge 和排序形成一个有序数组 int[],耗时主要集中在数组申请和排序。 - 稠密数据:基于 long[] 实现的 bitmap 结构(FixedBitSet),耗时主要集中在 FixedBitSet 的插入过程,由于倒排链需要实时 Decode 以及 FixedBitSet 的底层实现,无法实现批量 Merge,只能循环单个 Doc ID 插入,数据量大的情况下,耗时明显。
我们采用线上流量和数据压测发现该部分平均耗时约 7 ms。
4.2.2 RoaringBitmap
当前 Elasticsearch 选择 RoaringBitMap 做为 Query Cache 的底层数据结构缓存倒排链,加快查询速率。
RoaringBitmap 是一种压缩的位图,相较于常规的压缩位图能提供更好的压缩,在稀疏数据的场景下空间更有优势。以存放 Integer 为例,Roaring Bitmap 会对存入的数据进行分桶,每个桶都有自己对应的 Container。在存入一个32位的整数时,它会把整数划分为高 16 位和低 16 位,其中高 16 位决定该数据需要被分至哪个桶,我们只需要存储这个数据剩余的低 16 位,将低 16 位存储到 Container 中,若当前桶不存在数据,直接存储 null 节省空间。RoaringBitmap有不同的实现方式,下面以 Lucene 实现(RoaringDocIdSet)进行详细讲解:
如原理图中所示,RoaringBitmap 中存在两种不同的 Container:Bitmap Container 和 Array Container。

这两种 Container 分别对应不同的数据场景——若一个 Container 中的数据量小于 4096 个时,使用 Array Container 来存储。当 Array Container 中存放的数据量大于 4096 时,Roaring Bitmap 会将 Array Container 转为 Bitmap Container。即 Array Container 用于存放稀疏数据,而 Bitmap Container 用于存放稠密数据,这样做是为了充分利用空间。下图给出了随着容量增长 Array Container 和 Bitmap Container 的空间占用对比图,当元素个数达到 4096 后(每个元素占用 16 bit ),Array Container 的空间要大于 Bitmap Container。 备注:Roaring Bitmap 可参考官方博客[4]。
4.2.3 Index Sorting
Elasticsearch 从 6.0 版本开始支持 Index Sorting[5] 功能,在索引阶段可以配置多个字段进行排序,调整索引数据组织方式,可以调整文档所对应的 Doc ID。以 city_id,poi_id 为例:
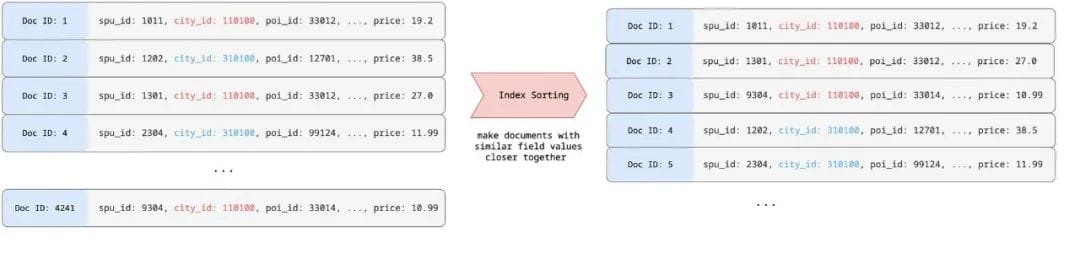
如上示例所示:Index Sorting 会将给定的排序字段(如上图的 city_id 字段)的文档排序在一起,相同排序值的文档的 Doc ID 严格自增,对该字段建立倒排,那么其倒排链为自增数列。
4.3 基于 RLE 的倒排格式设计
基于以上的背景知识以及当前 Elasticsearch/Lucene 的解决方案,可以明确目前有 2 个改造点需要考虑。
- 合适的倒排结构,用于存储每个 Term 的倒排链。
- 合适的中间结构,用于存储多个 Term 合并后的倒排链。
对于索引倒排格式 PostingsEnum,支持接口为:
public abstract class DocIdSetIterator {
public abstract int docID();
public abstract int nextDoc();
public abstract int advance(int target);
}
倒排仅支持单文档循环调用,不支持批量读取,因此需要为倒排增加批量顺序读取的功能。
对于多倒排链的合并,由于原结构 DocIdSetBuilder 的实现也不支持批量对数据进行合并,我们探索了评估了 Elasticsearch 用于缓存 Query Cache 的数据结构 RoaringBitMap,然而其实现 RoaringDocIdSet 也无法满足我们对缓存数据结构特性需求,主要问题:
- 原生 RoaringDocIdSet 在构建时,只能支持递增的添加 Doc ID。而在实际生产中每一个商家的商品的 Doc ID 都是离散的。这就限制了其使用范围。
- 原生 RoaringDocIdSet 的底层存储结构 Bitmap Container 和 Array Container 均不支持批量合并,这就无法满足我们对倒排链合并进行优化的需求。
在明确这个问题的场景下,我们可以考虑最简单的改造,支持索引倒排格式 PostingsEnum 的批量读取。并考虑了如下几种场景:
- 在支持批量读取倒排的情况下,直接使用原结构 DocIdSetBuilder 进行批量的合并。
- 在支持批量读取倒排的情况下,使用 RoaringBitMap 进行批量合并。
然而我们发现即使对 bitset 进行分段合并,直接对数据成段进行 OR 操作,整体开销下降并不明显。其原因主要在于:对于读取的批量结果,均为稀疏分布的 Doc ID,仅减少倒排的循环调用无法解决性能开销问题。
那么问题需要转化为如何解决 Doc ID 分布稀疏的问题。在上文提及的 Index Sorting 即一个绝佳的解决方案。并且由于业务 LBS 的特点,一次检索的全部结果集均集中在某个地理位置附近,以及我们检索仅针对门店列表 ID 的特殊场景,我们最终选择对城市 ID、 Geohash、门店 ID 进行排序,从而让稀疏分布的 Doc ID 形成连续分布。在这样的排序规则应用之后,我们得到了一组绝佳的特性:每一个商家所对应的商品,其 Doc ID 完全连续。
4.3.1 Run-Length Encoding
Run-Length Encoding[3](RLE)技术诞生于50年前,最早应用于连续的文本压缩及图像压缩。在 2014 年,第一个开源在 GitHub 的 RoaringBitmap 诞生[6],2016年,在 RoaringBitMap 的基础上增加了对于自增序列的 RLE 实现[7],并应用在 bitmap 这一场景上。
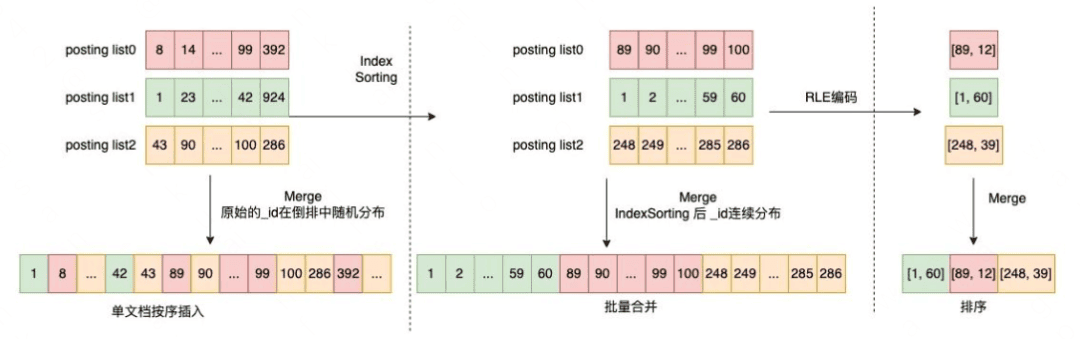
在 bitmap 这一场景之下,主要通过压缩连续区间的稠密数据,节省内存开销。以数组 [1, 2, 3, ..., 59, 60, 89, 90, 91, ..., 99, 100] 为例(如下图上半部分):使用 RLE 编码之后就变为 [1, 60, 89, 12]——形如 [start1, length1, start2, length2, ...] 的形式,其中第一位为连续数字的起始值,第二位为其长度。
在数组完全连续场景下中,对 32768 个 id (short) 进行存储,数组存储需要 64 kB,Bitmap 存储需要使用 4 kB,而 RLE 编码后直接存储仅需要 4 byte。在这一特性下,如果商家倒排链完全有序,那么商家的倒排链,可被压缩到最低仅需要两个整数即可表示。
当然 RLE 并不适用所有情况,在目标序列完全不连续的场景下,如 [1, 3, 5, 7, ... , M],RLE 编码存储需要使用 2 * M byte的空间,比数组直接存储的空间效率差一倍。
为了和 Elasticsearch 的实现保持一致,我们决定使用 RoaringBitMap 作为倒排存储的结构,以及中间结果合并的数据结构。针对 RoaringDocIdSet 我们进行了如下改造。
4.3.2 RLE Container 的实现
在对商家 ID 字段开启 Index Sorting 之后,同商家的商品 ID 已经连续分布。那么对于商家字段的倒排链就是严格自增且无空洞的整数序列。我们采用RLE编码对倒排链进行编码存储。由于将倒排链编码为 [start1, length1, start2, length2, ...],更特殊的,在我们场景下,一个倒排链的表示为 [start, length],RLE编码做到了对倒排链的极致压缩,假设倒排链为 [1, 2, ...., 1000], 用 ArrayContainer 存储,内存空间占用为 16 bit * 100 = 200 Byte, RLE 编码存储只需要 16 bit * 2 = 4 Byte。考虑到具体的场景分布,以及其他场景可能存在多段有序倒排的情况,我们最终选择了 [start1, length1, start2, length2, ...] 这样的存储格式,且 [start, start + length] 之间两两互不重叠。
对于多个商家的倒排合并流程,对于该格式的合并,我们并不需要对 M 个倒排链长度为 K 进行循环处理,这个问题转变为:如何对多组分段 [start, length] 进行排序,并将排序后的结果合并为一个数组。那么我们将原时间复杂度为 的合并流程,改造为复杂度为 O(M * logM) 的合并流程,大大降低了合并的计算耗时,减少了 CPU 的消耗。
4.3.3 SparseRoaringDocIdSet 实现
我们在 RoaringDocIdSet 的基础上增加了 RLE Container 后,性能已经得到了明显的提升,加速了 50%,然而依然不符合我们的预期。我们通过对倒排链的数据分析发现:倒排链的平均长度不大,基本在十万内。但是其取值范围广 [ 0, Integer.MAX-1 ]。这些特征说明,如果以 RoaringDocIdSet 按高 16 位进行分桶的话,大部分数据将集中在其中连续的几个桶中。
在 Elasticsearch 场景上,由于无法预估数据分布,RoaringDocIdSet 在申请 bucket 容器的数组时,会根据当前 Segment 中的最大 Doc ID 来申请,计算公式为:(maxDoc + (1 << 16) - 1) >>> 16。这种方式可以避免每次均按照 Integer.MAX-1 来创建容器带来的无谓开销。然而,当倒排链数量偏少且分布集中时,这种方式依然无法避免大量 bucket 被空置的空间浪费;另一方面,在对倒排链进行合并时,这些空置的 bucket 也会参与到遍历中,即使它被置为了空。这就又造成了性能上的浪费。我们通过压测评估证实了这一推理,即空置的 bucket 在合并时也会占用大量的 CPU 资源。
针对这一问题,我们设计了一套用于稀疏数据的方案,实现了 SparseRoaringDocIdSet,同时保持接口与 RoaringDocIdSet 一致,可在各场景下进行复用,其结构如下:
class SparseRoaringDocIdSet {
int[] index; // 记录有 container 的 bucket Index
Container[] denseSets; // 记录紧密排列的倒排链
}
保存倒排链的过程与 RoaringDocIDSet 保持一致,在确认具体的 Container 的分桶时,我们额外使用一组索引记录所有有值的 bucket 的 location。
下图是一组分别使用 RLE based RoaringDocIdSet 和 SparseRoaringDocIdSet 对 [846710, 100, 936858, 110] 倒排链(RLE 编码)进行存储的示意图:
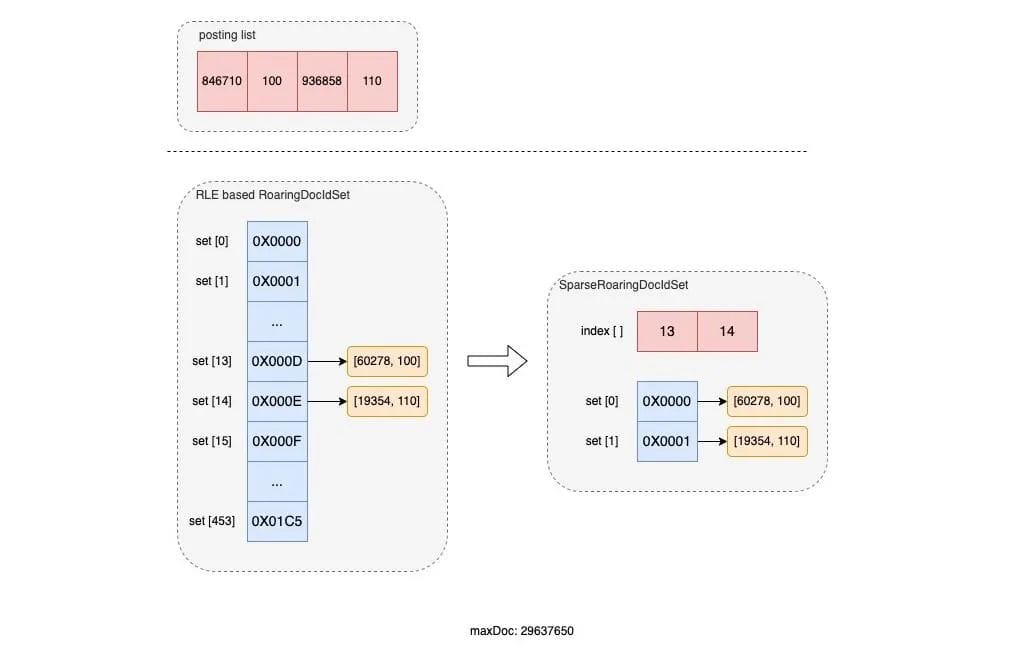
可以看到:在 SparseRoaringDocIdSet 实现下,所有不为空的 bucket 被紧密的排列在了一起,并在 index [] 中记录了其原始 bucket 的索引,这就避免了大量 bucket 被空置的情况。另外,在进行倒排链的合并时,就可以直接对紧密排列的 denseSet 进行遍历,并从 index [] 获得其对应的原始 bucket location,这就避免了大量的空置 bucket 在合并时带来的性能浪费。
我们分别对以下4个场景进行了压测:原生的 TermInSetQuery 对倒排链的合并逻辑、基于 FixedBitSet 的批量合并、RLE based RoaringBitmap、RLE based Dense RoaringBitmap。对 10000 个平均长度为 100 的倒排链进行合并压测,压测结果如下:
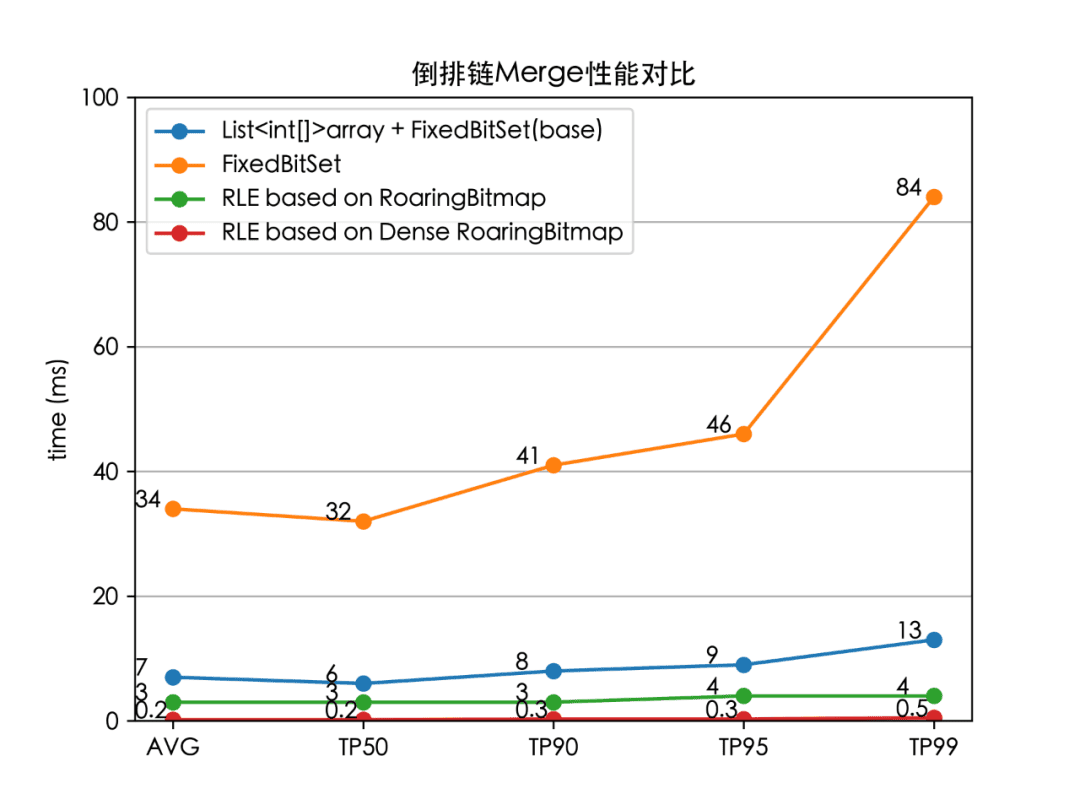
我们实现的 RLE based Dense RoaringBitmap,相比官方的基准实现耗时降低了 96%(TP99 13 ms 下降至 0.5 ms)。
4.4 功能集成
至此,核心的倒排索引问题已经解决,后续主要为工程问题:如何在 Elasticsearch 系统中集成基于 RLE 的倒排格式。对于高吞吐高并发的C端在线场景,我们希望尽可能保障线上的稳定,对开源数据格式的兼容,保障前向的兼容,做到随时可降级。
工程部分主要分为两部分:倒排索引的集成和在线检索链路。以下主要介绍全量索引部分的链路设计。
4.4.1 倒排索引集成
倒排索引格式的改造,一般情况下,需要实现一套 PostingsFormat,并实现对应的 Reader、Writer。为了保证对原有检索语句的兼容,支持多种场景的检索,以及为了未来能够无缝的配合 Elasticsearch 的版本升级,我们并没有选择直接实现一组新的 PostingsFormat,避免出现不兼容的情况导致无法升级版本。我们选择了基于现有的倒排格式,在服务加载前后初始化 RLE 倒排,并考虑到业务场景,我们决定将 RLE 倒排全量放入内存中,以达到极致的性能。具体的解决方案为:
- 索引加载过程中增加一组 Hook,用于获取现有的 InternalEngine( Elasticsearch中负责索引增删改查的主要对象 )。
- 对所有的 semgents 遍历读取数据,解析倒排数据。
- 对所有配置了 RLE 倒排优化的字段,生成 RLE 倒排表。
- 将 RLE 倒排表与 segment 做关联,保证后续的检索链路中能获取到倒排表。
为了避免内存泄漏,我们也将索引删除,segment 变更的场景进行了相应的处理。
4.4.2 在线检索链路
在线检索链路也采用了无侵入兼容的实现,我们实现了一套新的检索语句,并且在索引无 RLE 倒排的情况下,可以降级回原生的检索类型,更加安全。
我们基于 Elasticsearch 的插件机制,生成一组新的 Query,实现了其 AbstractQueryBuilder,实现对 Query 的解析与改写,并将 Query 与 RLE 倒排进行关联,我们通过改写具体的检索实现,将整个链路集成到 Elasticsearch 中。
5. 性能收益
对于 Elasticsearch 而言,一次检索分为这么几个阶段,可参考下图[8]。

- 由协调节点进行请求的分发,发送到各个检索节点上。
- 每个数据节点的各自进行检索,并返回检索结果给协调节点,这一段各个数据节点的耗时即“数据节点查询耗时”。
- 协调节点等待所有数据节点的返回,协调节点选取 Top K 后进行 fetch 操作。1~3 步的完整耗时为“完整链路查询耗时”。
我们将上述改动(Index Sorting + Dense Roaring Bitmap + RLE)上线到生产环境的商品索引后,性能如下: Image
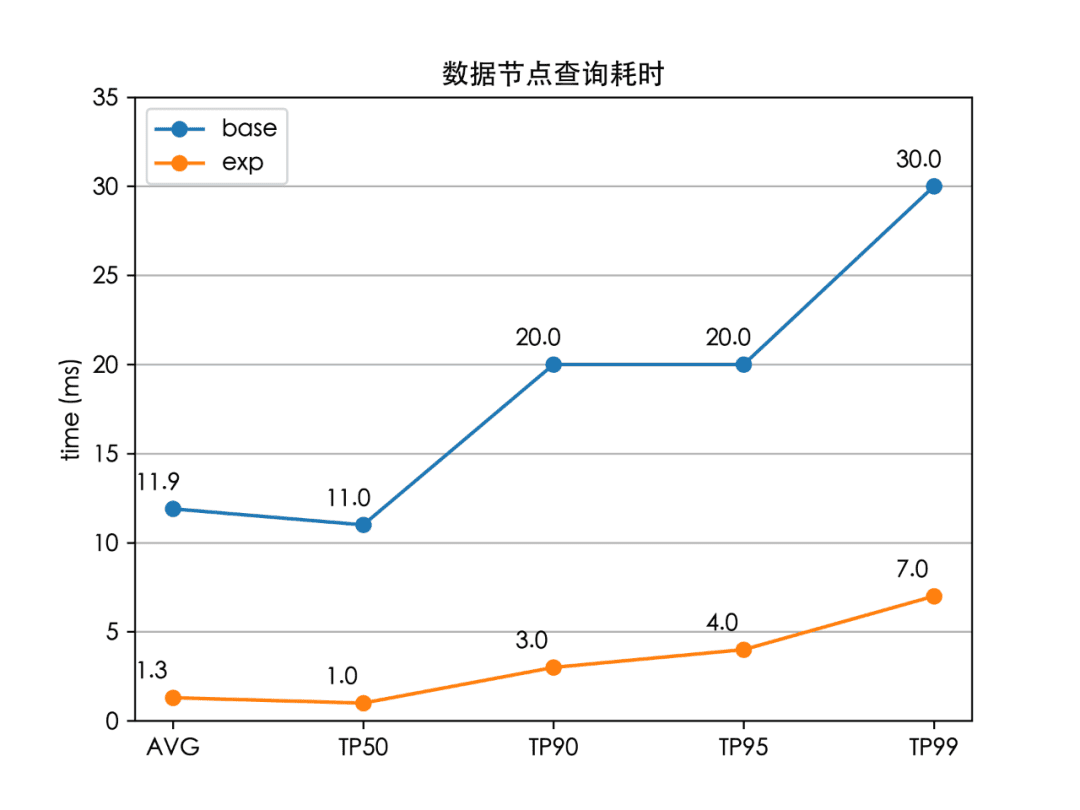
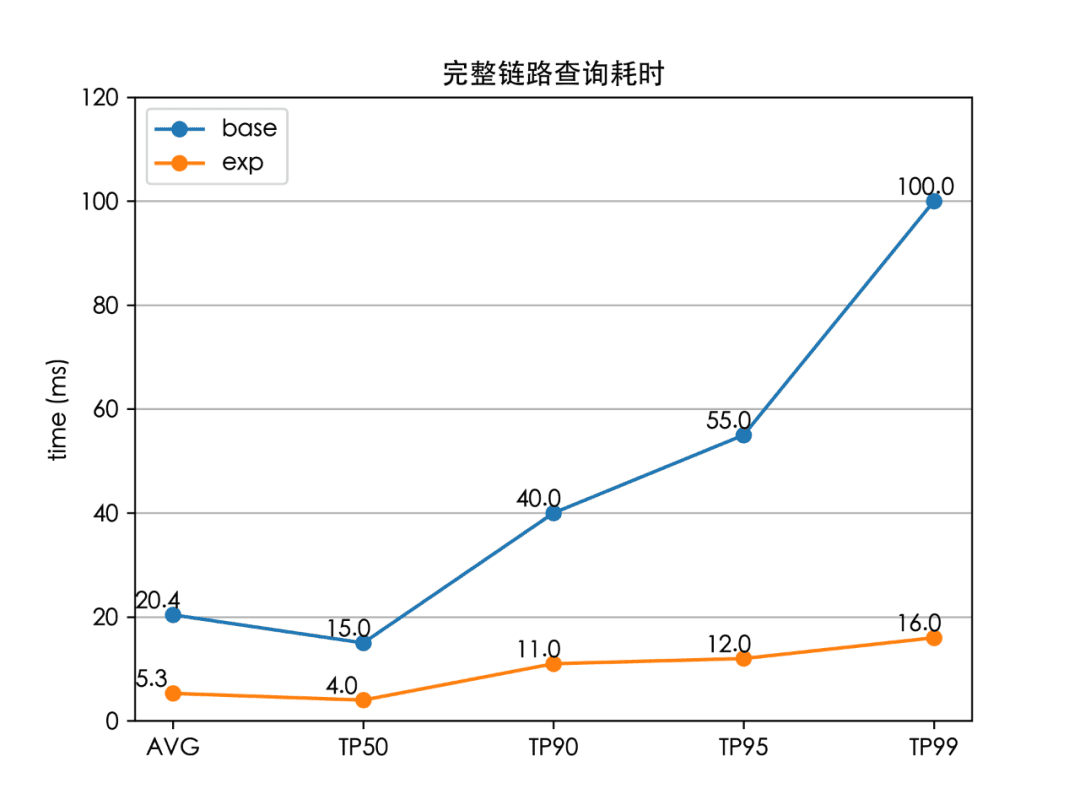
至此,我们成功将全链路的检索时延(TP99)降低了 84%(100 ms 下降至 16 ms),解决了外卖搜索的检索耗时问题,并且线上服务的 CPU 也大大降低。
6. 总结与展望
本文主要针对搜索业务场景中遇到的问题,进行问题分析、技术选型、压测、选择合适的解决方案、集成、灰度验证。我们最终实现了一套基于 RLE 倒排格式,作为一种新型的倒排格式,彻底解决了这个场景上的性能瓶颈,从分析至上线的流程长达数月。本文希望能提供一个思路,让其他同学在遇到 Elasticsearch 相关的性能问题时,也能遵循相同的路径,解决业务上的问题。
一般的,我们分析问题可以遵循这样的路径:
- 明确性能问题后,首先通过流量录制,获得一个用于后续基准压测的测试集合。
- 通过相关的性能分析工具,先明确是否存在 CPU 的热点或 IO 问题,对于 Java 技术栈,有很多常见的可用于分析性能的工具,美团内部有 Scaple 分析工具,外部可以使用 JProfiler、Java Flight Recorder、Async Profiler、Arthas、perf 这些工具。
- 对分析火焰图进行分析,配合源代码,进行数据分析和验证。
- 此外在 Elasticsearch 中还可以通过 Kibana 的 Search Profiler 用于协助定位问题。在录制大量的流量,抽样分析后,以我们的场景为例,进行 Profiler 后可以明确 TermInSetQuery 占用了一半以上的耗时。
- 明确问题后从索引、检索链路两侧进行分析,评估问题,进行多种解决方案的设计与尝试,通过 Java Microbenchmark Harness(JMH)代码基准测试工具,验证解决方案的有效性。
- 集成验证最终效果。

我们最终实现的关键点:
- 使用哈希表来实现索引 Term 的精确查找,以此减少倒排链的查询与读取的时间。
- 选取 RoaringBitmap 作为存储倒排链的数据结构,并与 RLE Container 相结合,实现对倒排链的压缩存储。当然,最重要的是,RLE 编码将倒排链的合并问题转换成了排序问题,实现了批量合并,从而大幅度减少了合并的性能消耗。
当然,我们的方案也还具有一些可以继续探索优化的地方。我们进行具体方案开发的时候,主要考虑解决我们特定场景的问题,做了一些定制化,以取得最大的性能收益。在一些更通用的场景上,也可以通过 RLE 倒排获得收益,例如根据数据的分布,自动选择 bitmap/array/RLE 容器,支持倒排链重叠的情况下的数据合并。
我们在发现也有论文与我们的想法不谋而合,有兴趣了解可以参考具体论文[9]。另外,在增量索引场景下,如果增量索引的变更量非常大,那么势必会遇到频繁更新内存 RLE 倒排的情况,这对内存和性能的消耗都不小,基于性能的考量,也可以直接将 RLE 倒排索引的结构固化到文件中,即在写索引时就完成对倒排链的编码,这样就能避免这一问题。
7. 作者简介
泽钰、张聪、晓鹏等,均来自美团到家事业群/搜索推荐技术部-搜索工程团队。
8. 参考文献
[1] https://en.wikipedia.org/wiki/Run-length_encoding
[2] https://www.elastic.co/guide/en/elasticsearch/reference/7.10/query-dsl-geo-polygon-query.html
[3] https://en.wikipedia.org/wiki/Finite-state_transducer [4] Frame of Reference and Roaring Bitmaps
[5] https://www.elastic.co/cn/blog/index-sorting-elasticsearch-6-0
[6] Chambi S, Lemire D, Kaser O, et al. Better bitmap performance with roaring bitmaps[J]. Software: practice and experience, 2016, 46(5): 709-719.
[7] Lemire D, Ssi‐Yan‐Kai G, Kaser O. Consistently faster and smaller compressed bitmaps with roaring[J]. Software: Practice and Experience, 2016, 46(11): 1547-1569.
[8] 检索两阶段流程:https://www.elastic.co/guide/cn/elasticsearch/guide/current/_fetch_phase.html#_fetch_phase
[9] Arroyuelo D, González S, Oyarzún M, et al. Document identifier reassignment and run-length-compressed inverted indexes for improved search performance[C]//Proceedings of the 36th international ACM SIGIR conference on Research and development in information retrieval. 2013: 173-182.