ES详解 - 聚合:聚合查询之Bucket聚合详解
ES详解 - 聚合:聚合查询之Bucket聚合详解
除了查询之外,最常用的聚合了,ElasticSearch提供了三种聚合方式: 桶聚合(Bucket Aggregation),指标聚合(Metric Aggregation) 和 管道聚合(Pipline Aggregation)。本文主要讲讲桶聚合(Bucket Aggregation)。
聚合的引入
我们在SQL结果中常有:
SELECT COUNT(color)
FROM table
GROUP BY color
ElasticSearch中桶在概念上类似于 SQL 的分组(GROUP BY),而指标则类似于 COUNT() 、 SUM() 、 MAX() 等统计方法。
进而引入了两个概念:
- 桶(Buckets) 满足特定条件的文档的集合
- 指标(Metrics) 对桶内的文档进行统计计算
所以ElasticSearch包含3种聚合(Aggregation)方式
桶聚合(Bucket Aggregation) - 本文中详解
指标聚合(Metric Aggregation) - 下文中讲解
管道聚合(Pipline Aggregation)
- 再下一篇讲解
- 聚合管道化,简单而言就是上一个聚合的结果成为下个聚合的输入;
(PS:指标聚合和桶聚合很多情况下是组合在一起使用的,其实你也可以看到,桶聚合本质上是一种特殊的指标聚合,它的聚合指标就是数据的条数count)
如何理解Bucket聚合
如果你直接去看文档,大概有几十种:

要么你需要花大量时间学习,要么你已经迷失或者即将迷失在知识点中...
所以你需要稍微站在设计者的角度思考下,不难发现设计上大概分为三类(当然有些是第二和第三类的融合)

(图中并没有全部列出内容,因为图要表达的意图我觉得还是比较清楚的,这就够了;有了这种思虑和认知,会大大提升你的认知效率。)
按知识点学习聚合
我们先按照官方权威指南中的一个例子,学习Aggregation中的知识点。
准备数据
让我们先看一个例子。我们将会创建一些对汽车经销商有用的聚合,数据是关于汽车交易的信息:车型、制造商、售价、何时被出售等。
首先我们批量索引一些数据:
POST /test-agg-cars/_bulk
{ "index": {}}
{ "price" : 10000, "color" : "red", "make" : "honda", "sold" : "2014-10-28" }
{ "index": {}}
{ "price" : 20000, "color" : "red", "make" : "honda", "sold" : "2014-11-05" }
{ "index": {}}
{ "price" : 30000, "color" : "green", "make" : "ford", "sold" : "2014-05-18" }
{ "index": {}}
{ "price" : 15000, "color" : "blue", "make" : "toyota", "sold" : "2014-07-02" }
{ "index": {}}
{ "price" : 12000, "color" : "green", "make" : "toyota", "sold" : "2014-08-19" }
{ "index": {}}
{ "price" : 20000, "color" : "red", "make" : "honda", "sold" : "2014-11-05" }
{ "index": {}}
{ "price" : 80000, "color" : "red", "make" : "bmw", "sold" : "2014-01-01" }
{ "index": {}}
{ "price" : 25000, "color" : "blue", "make" : "ford", "sold" : "2014-02-12" }
标准的聚合
有了数据,开始构建我们的第一个聚合。汽车经销商可能会想知道哪个颜色的汽车销量最好,用聚合可以轻易得到结果,用 terms 桶操作:
GET /test-agg-cars/_search
{
"size" : 0,
"aggs" : {
"popular_colors" : {
"terms" : {
"field" : "color.keyword"
}
}
}
}
- 聚合操作被置于顶层参数 aggs 之下(如果你愿意,完整形式 aggregations 同样有效)。
- 然后,可以为聚合指定一个我们想要名称,本例中是: popular_colors 。
- 最后,定义单个桶的类型 terms 。
结果如下:
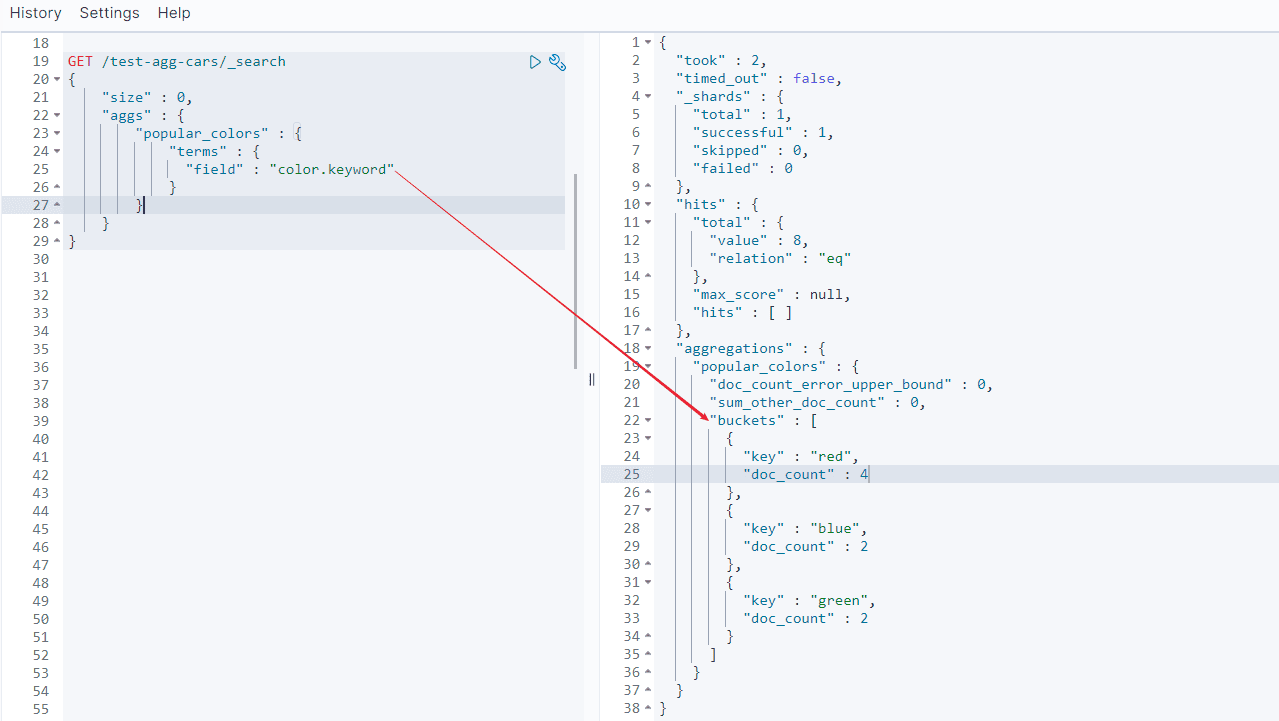
- 因为我们设置了 size 参数,所以不会有 hits 搜索结果返回。
- popular_colors 聚合是作为 aggregations 字段的一部分被返回的。
- 每个桶的 key 都与 color 字段里找到的唯一词对应。它总会包含 doc_count 字段,告诉我们包含该词项的文档数量。
- 每个桶的数量代表该颜色的文档数量。
多个聚合
同时计算两种桶的结果:对color和对make。
GET /test-agg-cars/_search
{
"size" : 0,
"aggs" : {
"popular_colors" : {
"terms" : {
"field" : "color.keyword"
}
},
"make_by" : {
"terms" : {
"field" : "make.keyword"
}
}
}
}
结果如下:

聚合的嵌套
这个新的聚合层让我们可以将 avg 度量嵌套置于 terms 桶内。实际上,这就为每个颜色生成了平均价格。
GET /test-agg-cars/_search
{
"size" : 0,
"aggs": {
"colors": {
"terms": {
"field": "color.keyword"
},
"aggs": {
"avg_price": {
"avg": {
"field": "price"
}
}
}
}
}
}
结果如下:
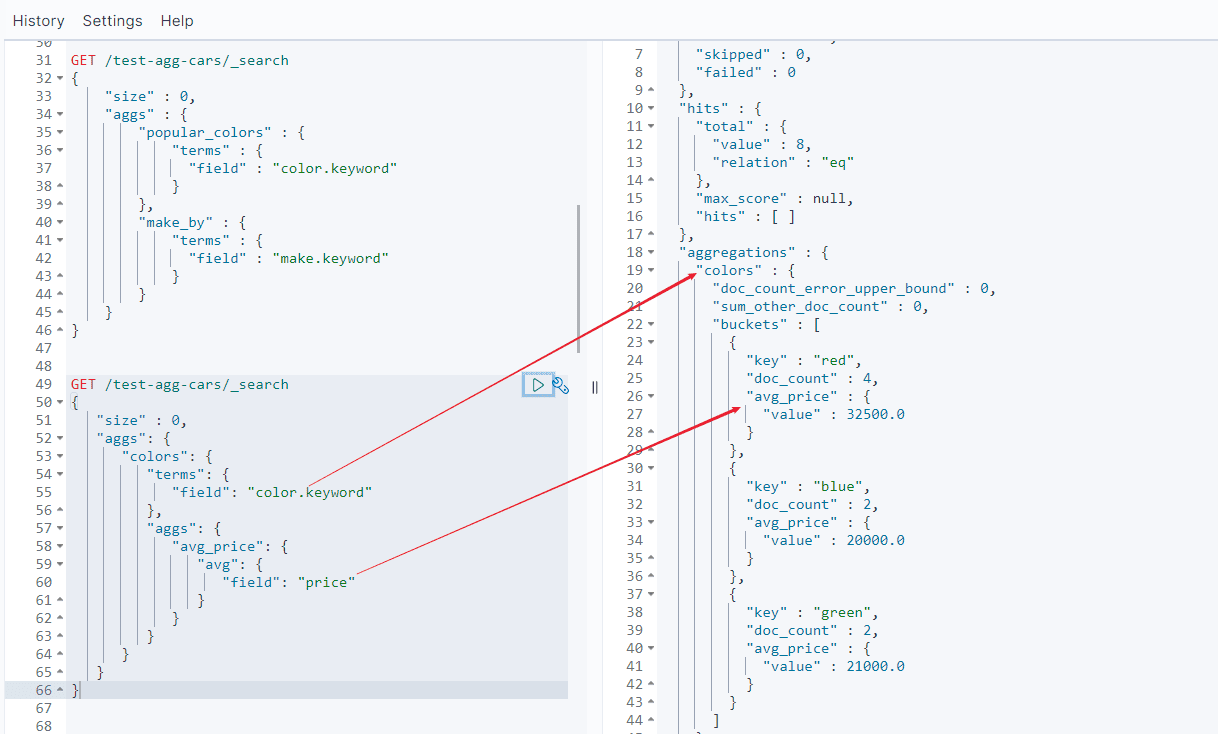
正如 颜色 的例子,我们需要给度量起一个名字( avg_price )这样可以稍后根据名字获取它的值。最后,我们指定度量本身( avg )以及我们想要计算平均值的字段( price )
动态脚本的聚合
这个例子告诉你,ElasticSearch还支持一些基于脚本(生成运行时的字段)的复杂的动态聚合。
GET /test-agg-cars/_search
{
"runtime_mappings": {
"make.length": {
"type": "long",
"script": "emit(doc['make.keyword'].value.length())"
}
},
"size" : 0,
"aggs": {
"make_length": {
"histogram": {
"interval": 1,
"field": "make.length"
}
}
}
}
结果如下:
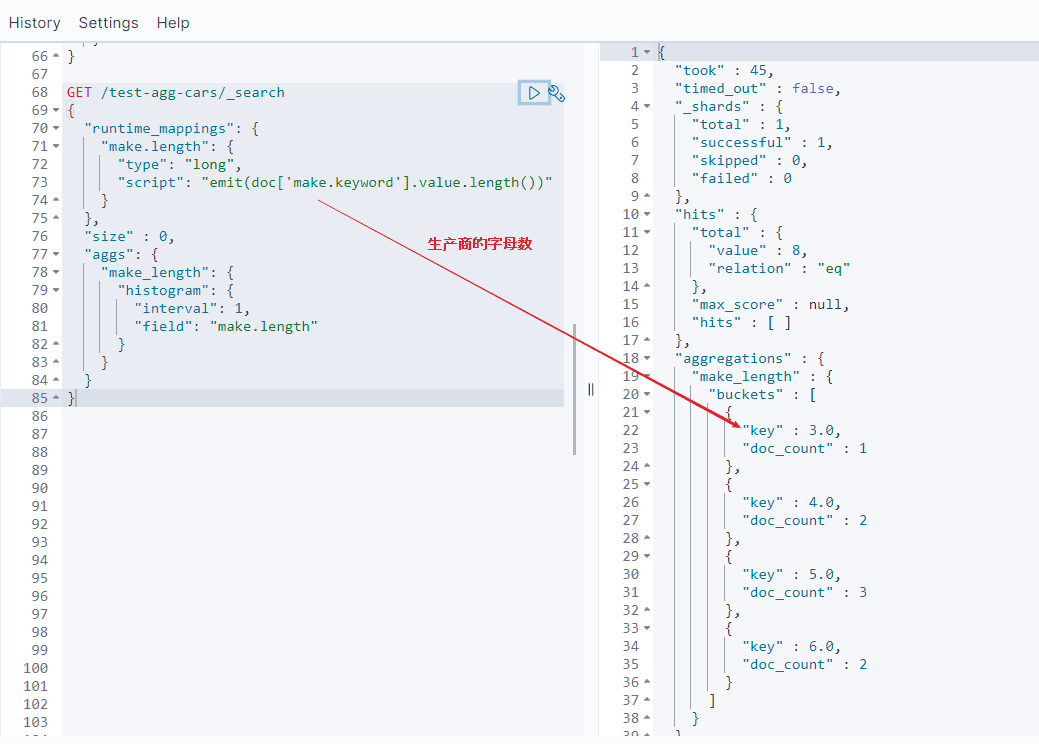
histogram可以参考后文内容。
按分类学习Bucket聚合
我们在具体学习时,也无需学习每一个点,基于上面图的认知,我们只需用20%的时间学习最为常用的80%功能即可,其它查查文档而已。
前置条件的过滤:filter
在当前文档集上下文中定义与指定过滤器(Filter)匹配的所有文档的单个存储桶。通常,这将用于将当前聚合上下文缩小到一组特定的文档。
GET /test-agg-cars/_search
{
"size": 0,
"aggs": {
"make_by": {
"filter": { "term": { "type": "honda" } },
"aggs": {
"avg_price": { "avg": { "field": "price" } }
}
}
}
}
结果如下:
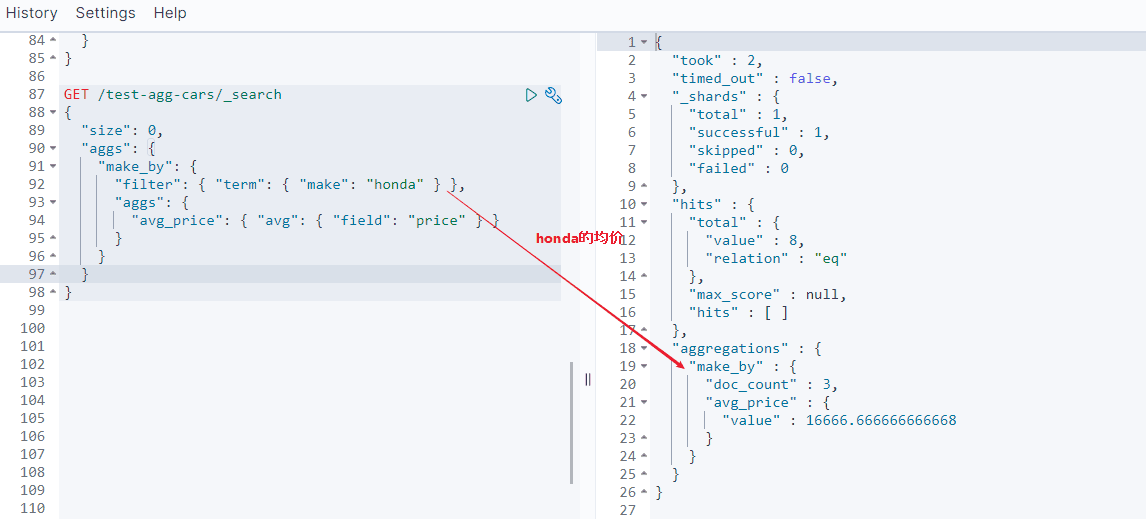
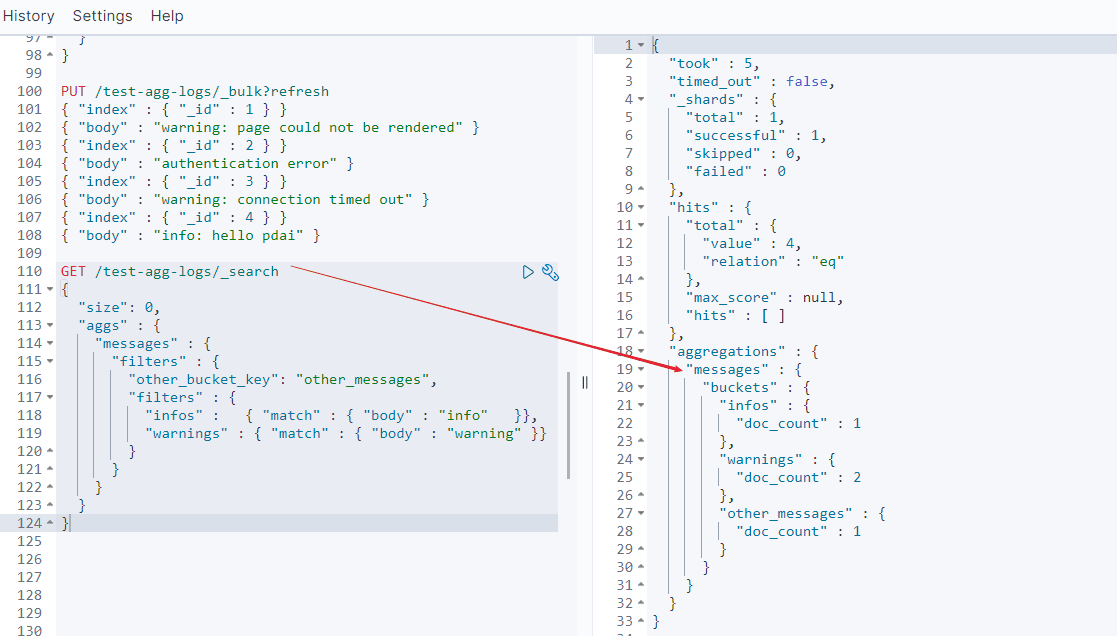
对filter进行分组聚合:filters
设计一个新的例子, 日志系统中,每条日志都是在文本中,包含warning/info等信息。
PUT /test-agg-logs/_bulk?refresh
{ "index" : { "_id" : 1 } }
{ "body" : "warning: page could not be rendered" }
{ "index" : { "_id" : 2 } }
{ "body" : "authentication error" }
{ "index" : { "_id" : 3 } }
{ "body" : "warning: connection timed out" }
{ "index" : { "_id" : 4 } }
{ "body" : "info: hello root" }
我们需要对包含不同日志类型的日志进行分组,这就需要filters:
GET /test-agg-logs/_search
{
"size": 0,
"aggs" : {
"messages" : {
"filters" : {
"other_bucket_key": "other_messages",
"filters" : {
"infos" : { "match" : { "body" : "info" }},
"warnings" : { "match" : { "body" : "warning" }}
}
}
}
}
}
结果如下:
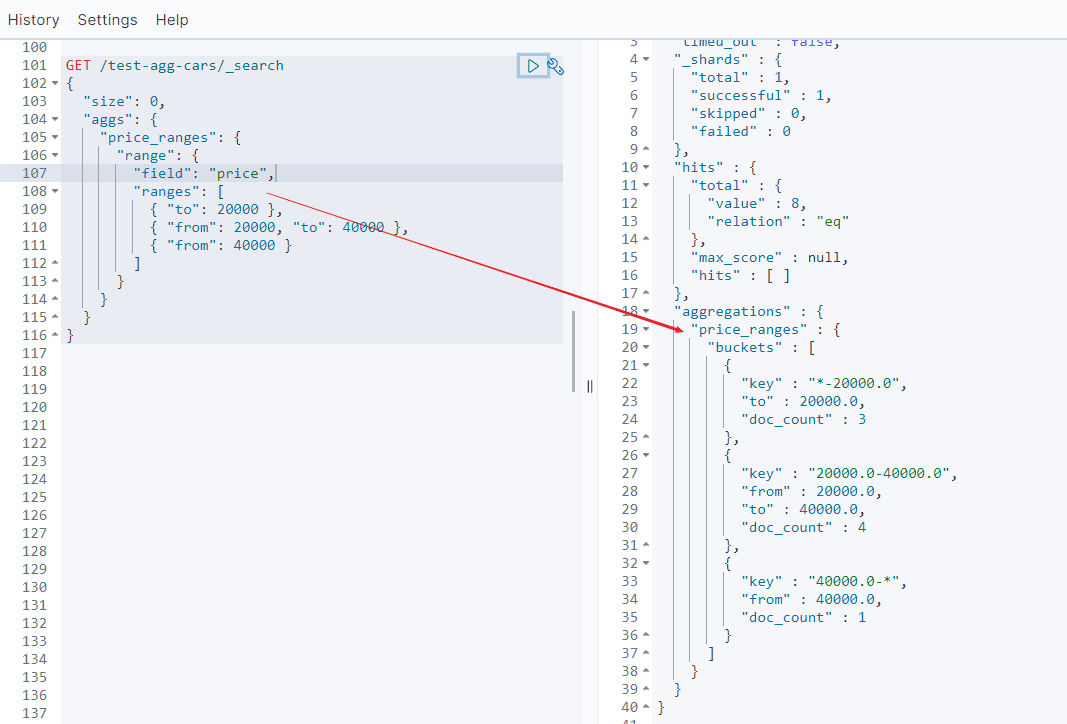
对number类型聚合:Range
基于多桶值源的聚合,使用户能够定义一组范围-每个范围代表一个桶。在聚合过程中,将从每个存储区范围中检查从每个文档中提取的值,并“存储”相关/匹配的文档。请注意,此聚合包括from值,但不包括to每个范围的值。
GET /test-agg-cars/_search
{
"size": 0,
"aggs": {
"price_ranges": {
"range": {
"field": "price",
"ranges": [
{ "to": 20000 },
{ "from": 20000, "to": 40000 },
{ "from": 40000 }
]
}
}
}
}
结果如下:
对IP类型聚合:IP Range
专用于IP值的范围聚合。
GET /ip_addresses/_search
{
"size": 10,
"aggs": {
"ip_ranges": {
"ip_range": {
"field": "ip",
"ranges": [
{ "to": "10.0.0.5" },
{ "from": "10.0.0.5" }
]
}
}
}
}
返回
{
...
"aggregations": {
"ip_ranges": {
"buckets": [
{
"key": "*-10.0.0.5",
"to": "10.0.0.5",
"doc_count": 10
},
{
"key": "10.0.0.5-*",
"from": "10.0.0.5",
"doc_count": 260
}
]
}
}
}
- CIDR Mask分组
此外还可以用CIDR Mask分组
GET /ip_addresses/_search
{
"size": 0,
"aggs": {
"ip_ranges": {
"ip_range": {
"field": "ip",
"ranges": [
{ "mask": "10.0.0.0/25" },
{ "mask": "10.0.0.127/25" }
]
}
}
}
}
返回
{
...
"aggregations": {
"ip_ranges": {
"buckets": [
{
"key": "10.0.0.0/25",
"from": "10.0.0.0",
"to": "10.0.0.128",
"doc_count": 128
},
{
"key": "10.0.0.127/25",
"from": "10.0.0.0",
"to": "10.0.0.128",
"doc_count": 128
}
]
}
}
}
- 增加key显示
GET /ip_addresses/_search
{
"size": 0,
"aggs": {
"ip_ranges": {
"ip_range": {
"field": "ip",
"ranges": [
{ "to": "10.0.0.5" },
{ "from": "10.0.0.5" }
],
"keyed": true // here
}
}
}
}
返回
{
...
"aggregations": {
"ip_ranges": {
"buckets": {
"*-10.0.0.5": {
"to": "10.0.0.5",
"doc_count": 10
},
"10.0.0.5-*": {
"from": "10.0.0.5",
"doc_count": 260
}
}
}
}
}
- 自定义key显示
GET /ip_addresses/_search
{
"size": 0,
"aggs": {
"ip_ranges": {
"ip_range": {
"field": "ip",
"ranges": [
{ "key": "infinity", "to": "10.0.0.5" },
{ "key": "and-beyond", "from": "10.0.0.5" }
],
"keyed": true
}
}
}
}
返回
{
...
"aggregations": {
"ip_ranges": {
"buckets": {
"infinity": {
"to": "10.0.0.5",
"doc_count": 10
},
"and-beyond": {
"from": "10.0.0.5",
"doc_count": 260
}
}
}
}
}
对日期类型聚合:Date Range
专用于日期值的范围聚合。
GET /test-agg-cars/_search
{
"size": 0,
"aggs": {
"range": {
"date_range": {
"field": "sold",
"format": "yyyy-MM",
"ranges": [
{ "from": "2014-01-01" },
{ "to": "2014-12-31" }
]
}
}
}
}
结果如下:

此聚合与Range聚合之间的主要区别在于 from和to值可以在Date Math表达式在新窗口打开中表示,并且还可以指定日期格式,通过该日期格式将返回from and to响应字段。请注意,此聚合包括from值,但不包括to每个范围的值。
对柱状图功能:Histrogram
直方图 histogram 本质上是就是为柱状图功能设计的。
创建直方图需要指定一个区间,如果我们要为售价创建一个直方图,可以将间隔设为 20,000。这样做将会在每个 $20,000 档创建一个新桶,然后文档会被分到对应的桶中。
对于仪表盘来说,我们希望知道每个售价区间内汽车的销量。我们还会想知道每个售价区间内汽车所带来的收入,可以通过对每个区间内已售汽车的售价求和得到。
可以用 histogram 和一个嵌套的 sum 度量得到我们想要的答案:
GET /test-agg-cars/_search
{
"size" : 0,
"aggs":{
"price":{
"histogram":{
"field": "price.keyword",
"interval": 20000
},
"aggs":{
"revenue": {
"sum": {
"field" : "price"
}
}
}
}
}
}
- histogram 桶要求两个参数:一个数值字段以及一个定义桶大小间隔。
- sum 度量嵌套在每个售价区间内,用来显示每个区间内的总收入。
如我们所见,查询是围绕 price 聚合构建的,它包含一个 histogram 桶。它要求字段的类型必须是数值型的同时需要设定分组的间隔范围。 间隔设置为 20,000 意味着我们将会得到如 [0-19999, 20000-39999, ...] 这样的区间。
接着,我们在直方图内定义嵌套的度量,这个 sum 度量,它会对落入某一具体售价区间的文档中 price 字段的值进行求和。 这可以为我们提供每个售价区间的收入,从而可以发现到底是普通家用车赚钱还是奢侈车赚钱。
响应结果如下:
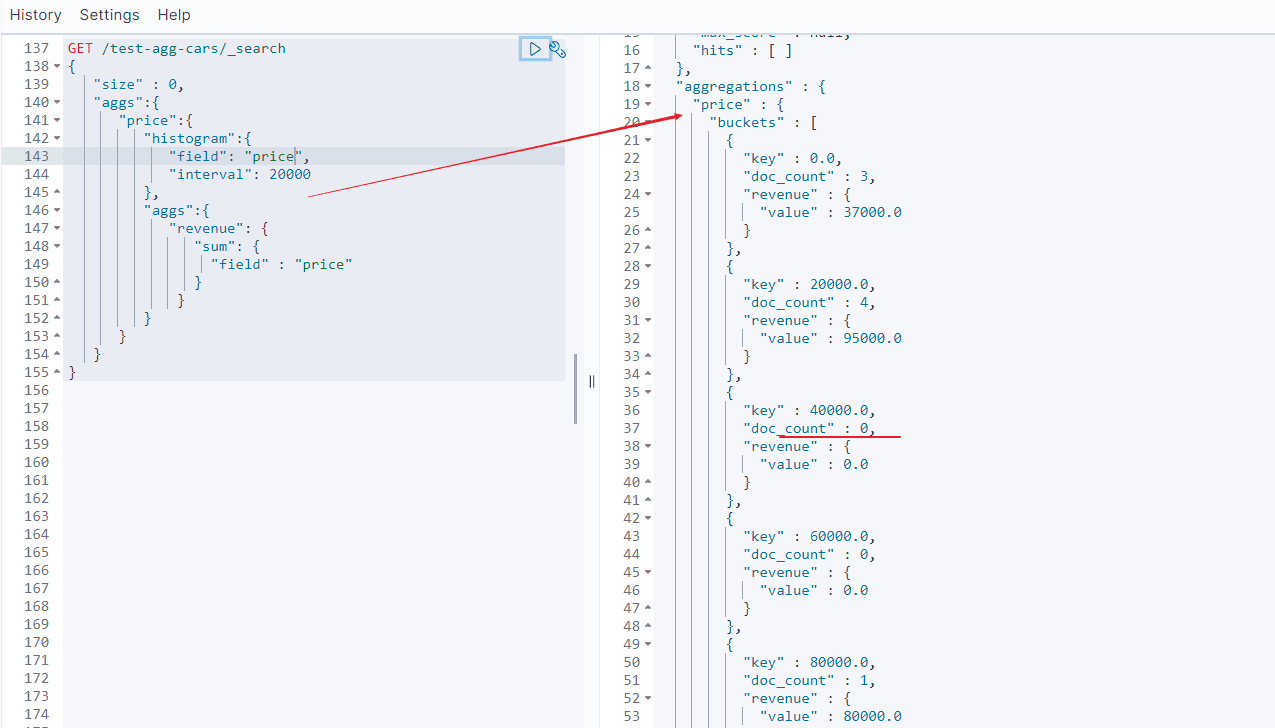
结果很容易理解,不过应该注意到直方图的键值是区间的下限。键 0 代表区间 0-19,999 ,键 20000 代表区间 20,000-39,999 ,等等。
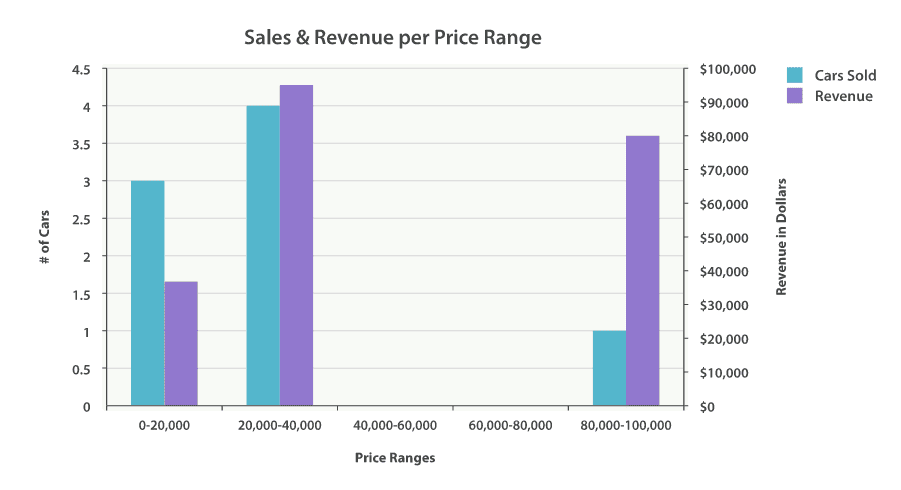
当然,我们可以为任何聚合输出的分类和统计结果创建条形图,而不只是 直方图 桶。让我们以最受欢迎 10 种汽车以及它们的平均售价、标准差这些信息创建一个条形图。 我们会用到 terms 桶和 extended_stats 度量:
GET /test-agg-cars/_search
{
"size" : 0,
"aggs": {
"makes": {
"terms": {
"field": "make.keyword",
"size": 10
},
"aggs": {
"stats": {
"extended_stats": {
"field": "price"
}
}
}
}
}
}
上述代码会按受欢迎度返回制造商列表以及它们各自的统计信息。我们对其中的 stats.avg 、 stats.count 和 stats.std_deviation 信息特别感兴趣,并用 它们计算出标准差:
std_err = std_deviation / count
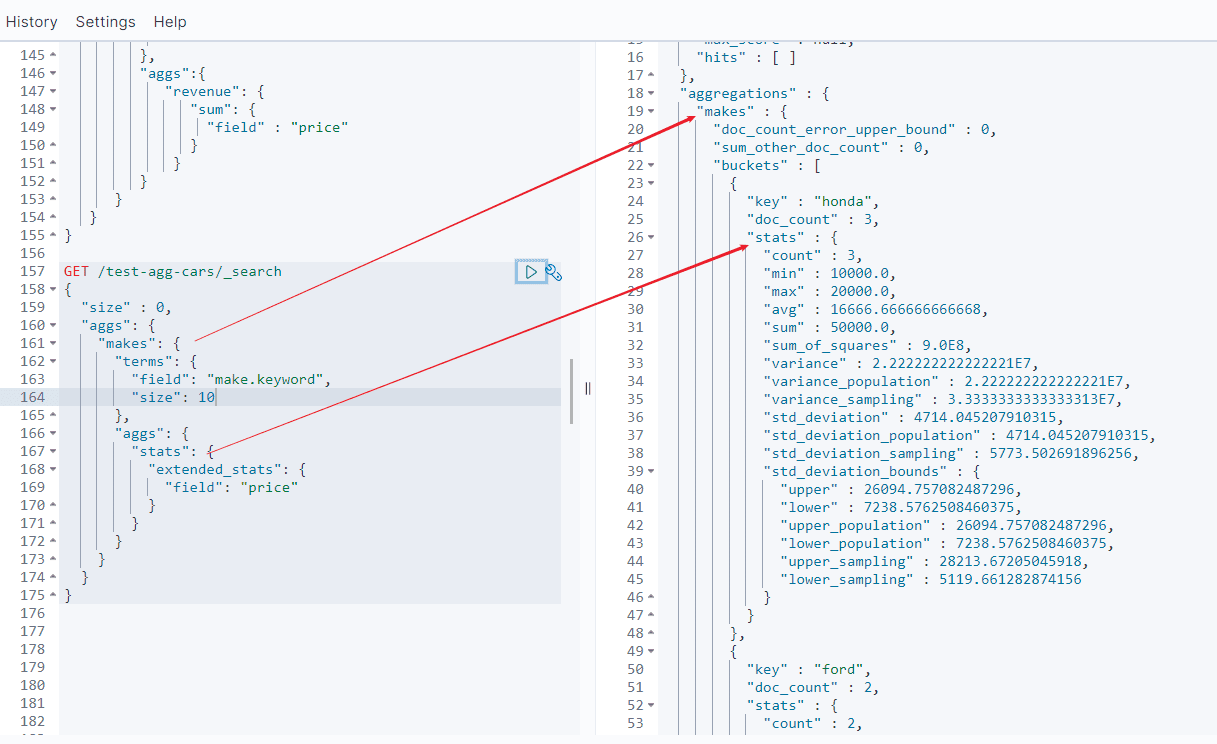
对应报表:

参考文章
https://www.elastic.co/guide/en/elasticsearch/reference/current/search-aggregations-bucket.html
https://www.elastic.co/guide/cn/elasticsearch/guide/current/_aggregation_test_drive.html