Java 11 升Java 17 重要特性必读
Java 11 升Java 17 重要特性必读
JDK 17 在 2021 年 9 月 14 号正式发布了!根据发布的规划,这次发布的 JDK 17 是一个长期维护的版本(LTS)。SpingFramework 6 和SpringBoot 3中默认将使用JDK 17,所以JDK 17必将是使用较广泛的版本; 而从上个LTS版本JDK11到JDK17有哪些重要特性需要掌握呢?本文帮助你梳理Java 11 升Java 17 重要特性。
升级JDK17概述
这里帮你梳理为何JDK 17将会是一个极为重要的版本以及如何去理解它。
JDK 17升级的必要性?
- JDK 11 作为一个 LTS版本,它的商业支持时间框架比 JDK 8 短,JDK 11 的 LTS 会提供技术支持直至 2023 年 9 月, 对应的补丁和安全警告等支持将持续至 2026 年。JDK 17 作为下一代 LTS 将提供至少到 2026 年的支持时间框架;
- Java系最为重要的开发框架Spring Framework 6 和 Spring Boot 3对JDK版本的最低要求是JDK 17;所以可以预见, 为了使用Spring最新框架,很多团队和开发者将被迫从Java 11(甚至Java 8)直接升级到Java 17版本。
JDK 11 升级到JDK 17 性能提升多少?
从规划调度引擎 OptaPlanner 项目(原文在这里在新窗口打开)对 JDK 17和 JDK 11 的性能基准测试进行了对比来看:
- 对于 G1GC(默认),Java 17 比 Java 11 快 8.66%;
- 对于 ParallelGC,Java 17 比 Java 11 快 6.54%;
- Parallel GC 整体比 G1 GC 快 16.39%
简而言之,JDK17 更快,高吞吐量垃圾回收器比低延迟垃圾回收器更快。
如何更好的理解从JDK 11 到 JDK 17 升级中带来的重要特性?
主要从如下三个方面理解,后续的章节主要围绕这三个方面进行:
- 语言新特性
- 新工具和库更新
- JVM优化
语言新特性
JDK14 - Switch 表达式(JDK 12,13预览,14正式)
switch 表达式在之前的 Java 12 和 Java 13 中都是处于预览阶段,而在这次更新的 Java 14 中,终于成为稳定版本,能够正式可用。
switch 表达式带来的不仅仅是编码上的简洁、流畅,也精简了 switch 语句的使用方式,同时也兼容之前的 switch 语句的使用;之前使用 switch 语句时,在每个分支结束之前,往往都需要加上 break 关键字进行分支跳出,以防 switch 语句一直往后执行到整个 switch 语句结束,由此造成一些意想不到的问题。switch 语句一般使用冒号 :来作为语句分支代码的开始,而 switch 表达式则提供了新的分支切换方式,即 -> 符号右则表达式方法体在执行完分支方法之后,自动结束 switch 分支,同时 -> 右则方法块中可以是表达式、代码块或者是手动抛出的异常。以往的 switch 语句写法如下:
int dayOfWeek;
switch (day) {
case MONDAY:
case FRIDAY:
case SUNDAY:
dayOfWeek = 6;
break;
case TUESDAY:
dayOfWeek = 7;
break;
case THURSDAY:
case SATURDAY:
dayOfWeek = 8;
break;
case WEDNESDAY:
dayOfWeek = 9;
break;
default:
dayOfWeek = 0;
break;
}
而现在 Java 14 可以使用 switch 表达式正式版之后,上面语句可以转换为下列写法:
int dayOfWeek = switch (day) {
case MONDAY, FRIDAY, SUNDAY -> 6;
case TUESDAY -> 7;
case THURSDAY, SATURDAY -> 8;
case WEDNESDAY -> 9;
default -> 0;
};
很明显,switch 表达式将之前 switch 语句从编码方式上简化了不少,但是还是需要注意下面几点:
- 需要保持与之前 switch 语句同样的 case 分支情况。
- 之前需要用变量来接收返回值,而现在直接使用 yield 关键字来返回 case 分支需要返回的结果。
- 现在的 switch 表达式中不再需要显式地使用 return、break 或者 continue 来跳出当前分支。
- 现在不需要像之前一样,在每个分支结束之前加上 break 关键字来结束当前分支,如果不加,则会默认往后执行,直到遇到 break 关键字或者整个 switch 语句结束,在 Java 14 表达式中,表达式默认执行完之后自动跳出,不会继续往后执行。
- 对于多个相同的 case 方法块,可以将 case 条件并列,而不需要像之前一样,通过每个 case 后面故意不加 break 关键字来使用相同方法块。
使用 switch 表达式来替换之前的 switch 语句,确实精简了不少代码,提高了编码效率,同时也可以规避一些可能由于不太经意而出现的意想不到的情况,可见 Java 在提高使用者编码效率、编码体验和简化使用方面一直在不停的努力中,同时也期待未来有更多的类似 lambda、switch 表达式这样的新特性出来。
JDK15 - 文本块(JDK 13,14预览,15正式)
文本块,是一个多行字符串,它可以避免使用大多数转义符号,自动以可预测的方式格式化字符串,并让开发人员在需要时可以控制格式。
Text Blocks首次是在JDK 13中以预览功能出现的,然后在JDK 14中又预览了一次,终于在JDK 15中被确定下来,可放心使用了。
public static void main(String[] args) {
String query = """
SELECT * from USER \
WHERE `id` = 1 \
ORDER BY `id`, `name`;\
""";
System.out.println(query);
}
运行程序,输出(可以看到展示为一行了):
SELECT * from USER WHERE `id` = 1 ORDER BY `id`, `name`;
JDK16 - instanceof 模式匹配(JDK 14,15预览,16正式)
模式匹配(Pattern Matching)最早在 Java 14 中作为预览特性引入,在 Java 15 中还是预览特性,在Java 16中成为正式版。模式匹配通过对 instacneof 运算符进行模式匹配来增强 Java 编程语言。
对 instanceof 的改进,主要目的是为了让创建对象更简单、简洁和高效,并且可读性更强、提高安全性。
在以往实际使用中,instanceof 主要用来检查对象的类型,然后根据类型对目标对象进行类型转换,之后进行不同的处理、实现不同的逻辑,具体可以参考如下:
if (person instanceof Student) {
Student student = (Student) person;
student.say();
// other student operations
} else if (person instanceof Teacher) {
Teacher teacher = (Teacher) person;
teacher.say();
// other teacher operations
}
上述代码中,我们首先需要对 person 对象进行类型判断,判断 person 具体是 Student 还是 Teacher,因为这两种角色对应不同操作,亦即对应到的实际逻辑实现,判断完 person 类型之后,然后强制对 person 进行类型转换为局部变量,以方便后续执行属于该角色的特定操作。
上面这种写法,有下面两个问题:
- 每次在检查类型之后,都需要强制进行类型转换。
- 类型转换后,需要提前创建一个局部变量来接收转换后的结果,代码显得多余且繁琐。
对 instanceof 进行模式匹配改进之后,上面示例代码可以改写成:
if (person instanceof Student student) {
student.say();
// other student operations
} else if (person instanceof Teacher teacher) {
teacher.say();
// other teacher operations
}
首先在 if 代码块中,对 person 对象进行类型匹配,校验 person 对象是否为 Student 类型,如果类型匹配成功,则会转换为 Student 类型,并赋值给模式局部变量 student,并且只有当模式匹配表达式匹配成功是才会生效和复制,同时这里的 student 变量只能在 if 块中使用,而不能在 else if/else 中使用,否则会报编译错误。
注意,如果 if 条件中有 && 运算符时,当 instanceof 类型匹配成功,模式局部变量的作用范围也可以相应延长,如下面代码:
if (obj instanceof String s && s.length() > 5) {.. s.contains(..) ..}
另外,需要注意,这种作用范围延长,并不适用于或 || 运算符,因为即便 || 运算符左边的 instanceof 类型匹配没有成功也不会造成短路,依旧会执行到||运算符右边的表达式,但是此时,因为 instanceof 类型匹配没有成功,局部变量并未定义赋值,此时使用会产生问题。
与传统写法对比,可以发现模式匹配不但提高了程序的安全性、健壮性,另一方面,不需要显式的去进行二次类型转换,减少了大量不必要的强制类型转换。模式匹配变量在模式匹配成功之后,可以直接使用,同时它还被限制了作用范围,大大提高了程序的简洁性、可读性和安全性。instanceof 的模式匹配,为 Java 带来的有一次便捷的提升,能够剔除一些冗余的代码,写出更加简洁安全的代码,提高码代码效率。
JDK16 - Records类型(JDK 14,15预览,16正式)
Records 最早在 Java 14 中作为预览特性引入,在 Java 15 中还是预览特性,在Java 16中成为正式版。
Record 类型允许在代码中使用紧凑的语法形式来声明类,而这些类能够作为不可变数据类型的封装持有者。Record 这一特性主要用在特定领域的类上;与枚举类型一样,Record 类型是一种受限形式的类型,主要用于存储、保存数据,并且没有其它额外自定义行为的场景下。
在以往开发过程中,被当作数据载体的类对象,在正确声明定义过程中,通常需要编写大量的无实际业务、重复性质的代码,其中包括:构造函数、属性调用、访问以及 equals() 、hashCode()、toString() 等方法,因此在 Java 14 中引入了 Record 类型,其效果有些类似 Lombok 的 @Data 注解、Kotlin 中的 data class,但是又不尽完全相同,它们的共同点都是类的部分或者全部可以直接在类头中定义、描述,并且这个类只用于存储数据而已。对于 Record 类型,具体可以用下面代码来说明:
public record Person(String name, int age) {
public static String address;
public String getName() {
return name;
}
}
对上述代码进行编译,然后反编译之后可以看到如下结果:
public final class Person extends java.lang.Record {
private final java.lang.String name;
private final java.lang.String age;
public Person(java.lang.String name, java.lang.String age) { /* compiled code */ }
public java.lang.String getName() { /* compiled code */ }
public java.lang.String toString() { /* compiled code */ }
public final int hashCode() { /* compiled code */ }
public final boolean equals(java.lang.Object o) { /* compiled code */ }
public java.lang.String name() { /* compiled code */ }
public java.lang.String age() { /* compiled code */ }
}
根据反编译结果,可以得出,当用 Record 来声明一个类时,该类将自动拥有下面特征:
- 拥有一个构造方法
- 获取成员属性值的方法:name()、age()
- hashCode() 方法和 euqals() 方法
- toString() 方法
- 类对象和属性被 final 关键字修饰,不能被继承,类的示例属性也都被 final 修饰,不能再被赋值使用。
- 还可以在 Record 声明的类中定义静态属性、方法和示例方法。注意,不能在 Record 声明的类中定义示例字段,类也不能声明为抽象类等。
可以看到,该预览特性提供了一种更为紧凑的语法来声明类,并且可以大幅减少定义类似数据类型时所需的重复性代码。
另外 Java 14 中为了引入 Record 这种新的类型,在 java.lang.Class 中引入了下面两个新方法:
RecordComponent[] getRecordComponents()
boolean isRecord()
其中 getRecordComponents() 方法返回一组 java.lang.reflect.RecordComponent 对象组成的数组,java.lang.reflect.RecordComponent也是一个新引入类,该数组的元素与 Record 类中的组件相对应,其顺序与在记录声明中出现的顺序相同,可以从该数组中的每个 RecordComponent 中提取到组件信息,包括其名称、类型、泛型类型、注释及其访问方法。
而 isRecord() 方法,则返回所在类是否是 Record 类型,如果是,则返回 true。
JDK17 - 密封的类和接口(JDK 15,16预览,17正式)
封闭类可以是封闭类和或者封闭接口,用来增强 Java 编程语言,防止其他类或接口扩展或实现它们。这个特性由Java 15的预览版本晋升为正式版本。
- 密封的类和接口解释和应用
因为我们引入了sealed class或interfaces,这些class或者interfaces只允许被指定的类或者interface进行扩展和实现。
使用修饰符sealed,您可以将一个类声明为密封类。密封的类使用reserved关键字permits列出可以直接扩展它的类。子类可以是最终的,非密封的或密封的。
之前我们的代码是这样的。
public class Person { } //人
class Teacher extends Person { }//教师
class Worker extends Person { } //工人
class Student extends Person{ } //学生
但是我们现在要限制 Person类 只能被这三个类继承,不能被其他类继承,需要这么做。
// 添加sealed修饰符,permits后面跟上只能被继承的子类名称
public sealed class Person permits Teacher, Worker, Student{ } //人
// 子类可以被修饰为 final
final class Teacher extends Person { }//教师
// 子类可以被修饰为 non-sealed,此时 Worker类就成了普通类,谁都可以继承它
non-sealed class Worker extends Person { } //工人
// 任何类都可以继承Worker
class AnyClass extends Worker{}
//子类可以被修饰为 sealed,同上
sealed class Student extends Person permits MiddleSchoolStudent,GraduateStudent{ } //学生
final class MiddleSchoolStudent extends Student { } //中学生
final class GraduateStudent extends Student { } //研究生
很强很实用的一个特性,可以限制类的层次结构。
新工具和库更新
JDK13 - Socket API 重构
Java 中的 Socket API 已经存在了二十多年了,尽管这么多年来,一直在维护和更新中,但是在实际使用中遇到一些局限性,并且不容易维护和调试,所以要对其进行大修大改,才能跟得上现代技术的发展,毕竟二十多年来,技术都发生了深刻的变化。Java 13 为 Socket API 带来了新的底层实现方法,并且在 Java 13 中是默认使用新的 Socket 实现,使其易于发现并在排除问题同时增加可维护性。
Java Socket API(java.net.ServerSocket 和 java.net.Socket)包含允许监听控制服务器和发送数据的套接字对象。可以使用 ServerSocket 来监听连接请求的端口,一旦连接成功就返回一个 Socket 对象,可以使用该对象读取发送的数据和进行数据写回操作,而这些类的繁重工作都是依赖于 SocketImpl 的内部实现,服务器的发送和接收两端都基于 SOCKS 进行实现的。
在 Java 13 之前,通过使用 PlainSocketImpl 作为 SocketImpl 的具体实现。
Java 13 中的新底层实现,引入 NioSocketImpl 的实现用以替换 SocketImpl 的 PlainSocketImpl 实现,此实现与 NIO(新 I/O)实现共享相同的内部基础结构,并且与现有的缓冲区高速缓存机制集成在一起,因此不需要使用线程堆栈。除了这些更改之外,还有其他一些更便利的更改,如使用 java.lang.ref.Cleaner 机制来关闭套接字(如果 SocketImpl 实现在尚未关闭的套接字上被进行了垃圾收集),以及在轮询时套接字处于非阻塞模式时处理超时操作等方面。
为了最小化在重新实现已使用二十多年的方法时出现问题的风险,在引入新实现方法的同时,之前版本的实现还未被移除,可以通过使用下列系统属性以重新使用原实现方法:
-Djdk.net.usePlainSocketImpl = true
另外需要注意的是,SocketImpl 是一种传统的 SPI 机制,同时也是一个抽象类,并未指定具体的实现,所以,新的实现方式尝试模拟未指定的行为,以达到与原有实现兼容的目的。但是,在使用新实现时,有些基本情况可能会失败,使用上述系统属性可以纠正遇到的问题,下面两个除外。
- 老版本中,PlainSocketImpl 中的 getInputStream() 和 getOutputStream() 方法返回的 InputStream 和 OutputStream 分别来自于其对应的扩展类型 FileInputStream 和 FileOutputStream,而这个在新版实现中则没有。
- 使用自定义或其它平台的 SocketImpl 的服务器套接字无法接受使用其他(自定义或其它平台)类型 SocketImpl 返回 Sockets 的连接。
通过这些更改,Java Socket API 将更易于维护,更好地维护将使套接字代码的可靠性得到改善。同时 NIO 实现也可以在基础层面完成,从而保持 Socket 和 ServerSocket 类层面上的不变。
JDK14 - 改进 NullPointerExceptions 提示信息
Java 14 改进 NullPointerException 的可查性、可读性,能更准确地定位 null 变量的信息。该特性能够帮助开发者和技术支持人员提高生产力,以及改进各种开发工具和调试工具的质量,能够更加准确、清楚地根据动态异常与程序代码相结合来理解程序。
相信每位开发者在实际编码过程中都遇到过 NullPointerException,每当遇到这种异常的时候,都需要根据打印出来的详细信息来分析、定位出现问题的原因,以在程序代码中规避或解决。例如,假设下面代码出现了一个 NullPointerException:
book.id = 99;
打印出来的 NullPointerException 信息如下:
Exception in thread "main" java.lang.NullPointerException
at Book.main(Book.java:5)
像上面这种异常,因为代码比较简单,并且异常信息中也打印出来了行号信息,开发者可以很快速定位到出现异常位置:book 为空而导致的 NullPointerException,而对于一些复杂或者嵌套的情况下出现 NullPointerException 时,仅根据打印出来的信息,很难判断实际出现问题的位置,具体见下面示例:
shoopingcart.buy.book.id = 99;
对于这种比较复杂的情况下,仅仅单根据异常信息中打印的行号,则比较难判断出现 NullPointerException 的原因。
而 Java 14 中,则做了对 NullPointerException 打印异常信息的改进增强,通过分析程序的字节码信息,能够做到准确的定位到出现 NullPointerException 的变量,并且根据实际源代码打印出详细异常信息,对于上述示例,打印信息如下:
Exception in thread "main" java.lang.NullPointerException:
Cannot assign field "book" because "shoopingcart.buy" is null
at Book.main(Book.java:5)
对比可以看出,改进之后的 NullPointerException 信息,能够准确打印出具体哪个变量导致的 NullPointerException,减少了由于仅带行号的异常提示信息带来的困惑。该改进功能可以通过如下参数开启:
-XX:+ShowCodeDetailsInExceptionMessages
该增强改进特性,不仅适用于属性访问,还适用于方法调用、数组访问和赋值等有可能会导致 NullPointerException 的地方。
JDK15 - 隐藏类 Hidden Classes
隐藏类是为框架(frameworks)所设计的,隐藏类不能直接被其他类的字节码使用,只能在运行时生成类并通过反射间接使用它们。
该提案通过启用标准 API 来定义 无法发现 且 具有有限生命周期 的隐藏类,从而提高 JVM 上所有语言的效率。JDK内部和外部的框架将能够动态生成类,而这些类可以定义隐藏类。通常来说基于JVM的很多语言都有动态生成类的机制,这样可以提高语言的灵活性和效率。
- 隐藏类天生为框架设计的,在运行时生成内部的class。
- 隐藏类只能通过反射访问,不能直接被其他类的字节码访问。
- 隐藏类可以独立于其他类加载、卸载,这可以减少框架的内存占用。
Hidden Classes是什么呢?
Hidden Classes就是不能直接被其他class的二进制代码使用的class。Hidden Classes主要被一些框架用来生成运行时类,但是这些类不是被用来直接使用的,而是通过反射机制来调用。
比如在JDK8中引入的lambda表达式,JVM并不会在编译的时候将lambda表达式转换成为专门的类,而是在运行时将相应的字节码动态生成相应的类对象。
另外使用动态代理也可以为某些类生成新的动态类。
那么我们希望这些动态生成的类需要具有什么特性呢?
- 不可发现性。 因为我们是为某些静态的类动态生成的动态类,所以我们希望把这个动态生成的类看做是静态类的一部分。所以我们不希望除了该静态类之外的其他机制发现。
- 访问控制。 我们希望在访问控制静态类的同时,也能控制到动态生成的类。
- 生命周期。 动态生成类的生命周期一般都比较短,我们并不需要将其保存和静态类的生命周期一致。
API的支持
所以我们需要一些API来定义无法发现的且具有有限生命周期的隐藏类。这将提高所有基于JVM的语言实现的效率。
比如:
java.lang.reflect.Proxy // 可以定义隐藏类作为实现代理接口的代理类。
java.lang.invoke.StringConcatFactory // 可以生成隐藏类来保存常量连接方法;
java.lang.invoke.LambdaMetaFactory //可以生成隐藏的nestmate类,以容纳访问封闭变量的lambda主体;
普通类是通过调用ClassLoader::defineClass创建的,而隐藏类是通过调用Lookup::defineHiddenClass创建的。这使JVM从提供的字节中派生一个隐藏类,链接该隐藏类,并返回提供对隐藏类的反射访问的查找对象。调用程序可以通过返回的查找对象来获取隐藏类的Class对象。
JDK15 - DatagramSocket API重构
重新实现了老的 DatagramSocket API 接口,更改了 java.net.DatagramSocket 和 java.net.MulticastSocket 为更加简单、现代化的底层实现,更易于维护和调试。
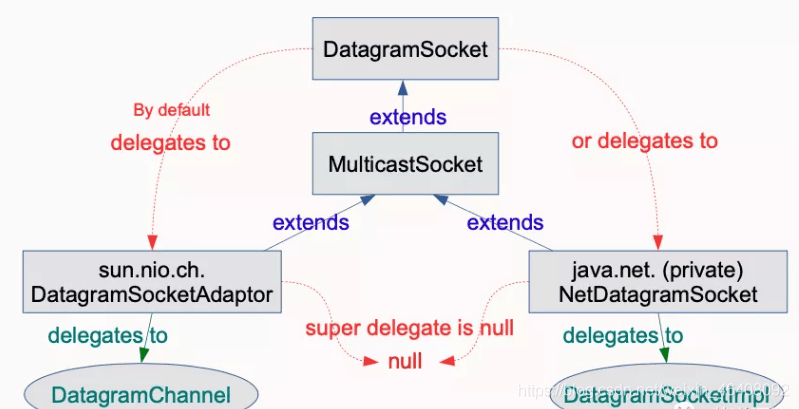
java.net.datagram.Socket和java.net.MulticastSocket的当前实现可以追溯到JDK 1.0,那时IPv6还在开发中。因此,当前的多播套接字实现尝试调和IPv4和IPv6难以维护的方式。
- 通过替换 java.net.datagram 的基础实现,重新实现旧版 DatagramSocket API。
- 更改
java.net.DatagramSocket和java.net.MulticastSocket为更加简单、现代化的底层实现。提高了 JDK 的可维护性和稳定性。 - 通过将
java.net.datagram.Socket和java.net.MulticastSocketAPI的底层实现替换为更简单、更现代的实现来重新实现遗留的DatagramSocket API。
新的实现:
- 易于调试和维护;
- 与Project Loom中正在探索的虚拟线程协同。
JDK16 - 对基于值的类发出警告
JDK9注解@Deprecated得到了增强,增加了 since 和 forRemoval 两个属性,可以分别指定一个程序元素被废弃的版本,以及是否会在今后的版本中被删除。JDK16中对
@jdk.internal.ValueBased注解加入了基于值的类的告警,所以继续在 Synchronized 同步块中使用值类型,将会在编译期和运行期产生警告,甚至是异常。
- JDK9中@Deprecated增强了增加了 since 和 forRemoval 两 个属性
JDK9注解@Deprecated得到了增强,增加了 since 和 forRemoval 两个属性,可以分别指定一个程序元素被废弃的版本,以及是否会在今后的版本中被删除。
在如下的代码中,表示PdaiDeprecatedTest这个类在JDK9版本中被弃用并且在将来的某个版本中一定会被删除。
@Deprecated(since="9", forRemoval = true)
public class PdaiDeprecatedTest {
}
- JDK16中对基于值的类(@jdk.internal.ValueBased)给出告警
在JDK9中我们可以看到Integer.java类构造函数中加入了@Deprecated(since="9"),表示在JDK9版本中被弃用并且在将来的某个版本中一定会被删除
public final class Integer extends Number implements Comparable<Integer> {
// ...
/**
* Constructs a newly allocated {@code Integer} object that
* represents the specified {@code int} value.
*
* @param value the value to be represented by the
* {@code Integer} object.
*
* @deprecated
* It is rarely appropriate to use this constructor. The static factory
* {@link #valueOf(int)} is generally a better choice, as it is
* likely to yield significantly better space and time performance.
*/
@Deprecated(since="9")
public Integer(int value) {
this.value = value;
}
// ...
}
如下是JDK16中Integer.java的代码
/*
* <p>This is a <a href="{@docRoot}/java.base/java/lang/doc-files/ValueBased.html">value-based</a>
* class; programmers should treat instances that are
* {@linkplain #equals(Object) equal} as interchangeable and should not
* use instances for synchronization, or unpredictable behavior may
* occur. For example, in a future release, synchronization may fail.
*
* <p>Implementation note: The implementations of the "bit twiddling"
* methods (such as {@link #highestOneBit(int) highestOneBit} and
* {@link #numberOfTrailingZeros(int) numberOfTrailingZeros}) are
* based on material from Henry S. Warren, Jr.'s <i>Hacker's
* Delight</i>, (Addison Wesley, 2002).
*
* @author Lee Boynton
* @author Arthur van Hoff
* @author Josh Bloch
* @author Joseph D. Darcy
* @since 1.0
*/
@jdk.internal.ValueBased
public final class Integer extends Number
implements Comparable<Integer>, Constable, ConstantDesc {
// ...
/**
* Constructs a newly allocated {@code Integer} object that
* represents the specified {@code int} value.
*
* @param value the value to be represented by the
* {@code Integer} object.
*
* @deprecated
* It is rarely appropriate to use this constructor. The static factory
* {@link #valueOf(int)} is generally a better choice, as it is
* likely to yield significantly better space and time performance.
*/
@Deprecated(since="9", forRemoval = true)
public Integer(int value) {
this.value = value;
}
// ...
添加@jdk.internal.ValueBased和@Deprecated(since="9", forRemoval = true)的作用是什么呢?
- JDK设计者建议使用Integer a = 10或者Integer.valueOf()函数,而不是new Integer(),让其抛出告警?
在构造函数上都已经标记有@Deprecated(since="9", forRemoval = true)注解,这就意味着其构造函数在将来会被删除,不应该在程序中继续使用诸如new Integer(); 如果继续使用,编译期将会产生'Integer(int)' is deprecated and marked for removal 告警。
- 在并发环境下,Integer 对象根本无法通过 Synchronized 来保证线程安全,让其抛出告警?
由于JDK中对@jdk.internal.ValueBased注解加入了基于值的类的告警,所以继续在 Synchronized 同步块中使用值类型,将会在编译期和运行期产生警告,甚至是异常。
public void inc(Integer count) {
for (int i = 0; i < 10; i++) {
new Thread(() -> {
synchronized (count) { // 这里会产生编译告警
count++;
}
}).start();
}
}
JDK17 - 增强的伪随机数生成器
为伪随机数生成器 (PRNG) 提供新的接口类型和实现。这一变化提高了不同 PRNG 的互操作性,并使得根据需求请求算法变得容易,而不是硬编码特定的实现。简单而言只需要理解如下三个问题:
JDK 17之前如何生成随机数?
- Random 类
典型的使用如下,随机一个int值
// random int
new Random().nextInt();
/**
* description 获取指定位数的随机数
*
* @param length 1
* @return java.lang.String
*/
public static String getRandomString(int length) {
String base = "abcdefghijklmnopqrstuvwxyz0123456789";
Random random = new Random();
StringBuilder sb = new StringBuilder();
for (int i = 0; i < length; i++) {
int number = random.nextInt(base.length());
sb.append(base.charAt(number));
}
return sb.toString();
}
- ThreadLocalRandom 类
提供线程间独立的随机序列。它只有一个实例,多个线程用到这个实例,也会在线程内部各自更新状态。它同时也是 Random 的子类,不过它几乎把所有 Random 的方法又实现了一遍。
/**
* nextInt(bound) returns 0 <= value < bound; repeated calls produce at
* least two distinct results
*/
public void testNextIntBounded() {
// sample bound space across prime number increments
for (int bound = 2; bound < MAX_INT_BOUND; bound += 524959) {
int f = ThreadLocalRandom.current().nextInt(bound);
assertTrue(0 <= f && f < bound);
int i = 0;
int j;
while (i < NCALLS &&
(j = ThreadLocalRandom.current().nextInt(bound)) == f) {
assertTrue(0 <= j && j < bound);
++i;
}
assertTrue(i < NCALLS);
}
}
- SplittableRandom 类
非线程安全,但可以 fork 的随机序列实现,适用于拆分子任务的场景。
/**
* Repeated calls to nextLong produce at least two distinct results
*/
public void testNextLong() {
SplittableRandom sr = new SplittableRandom();
long f = sr.nextLong();
int i = 0;
while (i < NCALLS && sr.nextLong() == f)
++i;
assertTrue(i < NCALLS);
}
为什么需要增强?
- 上述几个类实现代码质量和接口抽象不佳
- 缺少常见的伪随机算法
- 自定义扩展随机数的算法只能自己去实现,缺少统一的接口
增强后是什么样的?
代码的优化自不必说,我们就看下新增了哪些常见的伪随机算法

如何使用这个呢?可以使用RandomGenerator
RandomGenerator g = RandomGenerator.of("L64X128MixRandom");
JVM优化
JDK13 - 增强 ZGC 释放未使用内存
ZGC 是 Java 11 中引入的最为瞩目的垃圾回收特性,是一种可伸缩、低延迟的垃圾收集器,不过在 Java 11 中是实验性的引入,主要用来改善 GC 停顿时间,并支持几百 MB 至几个 TB 级别大小的堆,并且应用吞吐能力下降不会超过 15%,目前只支持 Linux/x64 位平台的这样一种新型垃圾收集器。
通过在实际中的使用,发现 ZGC 收集器中并没有像 Hotspot 中的 G1 和 Shenandoah 垃圾收集器一样,能够主动将未使用的内存释放给操作系统的功能。对于大多数应用程序来说,CPU 和内存都属于有限的紧缺资源,特别是现在使用的云上或者虚拟化环境中。如果应用程序中的内存长期处于空闲状态,并且还不能释放给操作系统,这样会导致其他需要内存的应用无法分配到需要的内存,而这边应用分配的内存还处于空闲状态,处于”忙的太忙,闲的太闲”的非公平状态,并且也容易导致基于虚拟化的环境中,因为这些实际并未使用的资源而多付费的情况。由此可见,将未使用内存释放给系统主内存是一项非常有用且亟需的功能。
ZGC 堆由一组称为 ZPages 的堆区域组成。在 GC 周期中清空 ZPages 区域时,它们将被释放并返回到页面缓存 ZPageCache 中,此缓存中的 ZPages 按最近最少使用(LRU)的顺序,并按照大小进行组织。在 Java 13 中,ZGC 将向操作系统返回被标识为长时间未使用的页面,这样它们将可以被其他进程重用。同时释放这些未使用的内存给操作系统不会导致堆大小缩小到参数设置的最小大小以下,如果将最小和最大堆大小设置为相同的值,则不会释放任何内存给操作系统。
Java 13 中对 ZGC 的改进,主要体现在下面几点:
- 释放未使用内存给操作系统
- 支持最大堆大小为 16TB
- 添加参数:-XX:SoftMaxHeapSize 来软限制堆大小
这里提到的是软限制堆大小,是指 GC 应努力是堆大小不要超过指定大小,但是如果实际需要,也还是允许 GC 将堆大小增加到超过 SoftMaxHeapSize 指定值。主要用在下面几种情况:当希望降低堆占用,同时保持应对堆空间临时增加的能力,亦或想保留充足内存空间,以能够应对内存分配,而不会因为内存分配意外增加而陷入分配停滞状态。不应将 SoftMaxHeapSize 设置为大于最大堆大小(-Xmx 的值,如果未在命令行上设置,则此标志应默认为最大堆大小。
Java 13 中,ZGC 内存释放功能,默认情况下是开启的,不过可以使用参数:-XX:-ZUncommit 显式关闭,同时如果将最小堆大小 (-Xms) 配置为等于最大堆大小 (-Xmx),则将隐式禁用此功能。
还可以使用参数:-XX:ZUncommitDelay = <seconds>(默认值为 300 秒)来配置延迟释放,此延迟时间可以指定释放多长时间之前未使用的内存。
JDK14 - G1 的 NUMA 可识别内存分配
Java 14 改进非一致性内存访问(NUMA)系统上的 G1 垃圾收集器的整体性能,主要是对年轻代的内存分配进行优化,从而提高 CPU 计算过程中内存访问速度。
NUMA 是 non-unified memory access 的缩写,主要是指在当前的多插槽物理计算机体系中,比较普遍是多核的处理器,并且越来越多的具有 NUMA 内存访问体系结构,即内存与每个插槽或内核之间的距离并不相等。同时套接字之间的内存访问具有不同的性能特征,对更远的套接字的访问通常具有更多的时间消耗。这样每个核对于每一块或者某一区域的内存访问速度会随着核和物理内存所在的位置的远近而有不同的时延差异。
Java 中,堆内存分配一般发生在线程运行的时候,当创建了一个新对象时,该线程会触发 G1 去分配一块内存出来,用来存放新创建的对象,在 G1 内存体系中,其实就是一块 region(大对象除外,大对象需要多个 region),在这个分配新内存的过程中,如果支持了 NUMA 感知内存分配,将会优先在与当前线程所绑定的 NUMA 节点空闲内存区域来执行 allocate 操作,同一线程创建的对象,尽可能的保留在年轻代的同一 NUMA 内存节点上,因为是基于同一个线程创建的对象大部分是短存活并且高概率互相调用的。
具体启用方式可以在 JVM 参数后面加上如下参数:
-XX:+UseNUMA
通过这种方式来启用可识别的内存分配方式,能够提高一些大型计算机的 G1 内存分配回收性能。
JDK14 - 删除 CMS 垃圾回收器
CMS 是老年代垃圾回收算法,通过标记-清除的方式进行内存回收,在内存回收过程中能够与用户线程并行执行。CMS 回收器可以与 Serial 回收器和 Parallel New 回收器搭配使用,CMS 主要通过并发的方式,适当减少系统的吞吐量以达到追求响应速度的目的,比较适合在追求 GC 速度的服务器上使用。
因为 CMS 回收算法在进行 GC 回收内存过程中是使用并行方式进行的,如果服务器 CPU 核数不多的情况下,进行 CMS 垃圾回收有可能造成比较高的负载。同时在 CMS 并行标记和并行清理时,应用线程还在继续运行,程序在运行过程中自然会创建新对象、释放不用对象,所以在这个过程中,会有新的不可达内存地址产生,而这部分的不可达内存是出现在标记过程结束之后,本轮 CMS 回收无法在周期内将它们回收掉,只能留在下次垃圾回收周期再清理掉。这样的垃圾就叫做浮动垃圾。由于垃圾收集和用户线程是并发执行的,因此 CMS 回收器不能像其他回收器那样进行内存回收,需要预留一些空间用来保存用户新创建的对象。由于 CMS 回收器在老年代中使用标记-清除的内存回收策略,势必会产生内存碎片,内存当碎片过多时,将会给大对象分配带来麻烦,往往会出现老年代还有空间但不能再保存对象的情况。
所以,早在几年前的 Java 9 中,就已经决定放弃使用 CMS 回收器了,而这次在 Java 14 中,是继之前 Java 9 中放弃使用 CMS 之后,彻底将其禁用,并删除与 CMS 有关的选项,同时清除与 CMS 有关的文档内容,至此曾经辉煌一度的 CMS 回收器,也将成为历史。
当在 Java 14 版本中,通过使用参数: -XX:+UseConcMarkSweepGC,尝试使用 CMS 时,将会收到下面信息:
Java HotSpot(TM) 64-Bit Server VM warning: Ignoring option UseConcMarkSweepGC; \
support was removed in <version>
JDK14 - 弃用 ParallelScavenge 和 SerialOld GC 的组合使用
由于 Parallel Scavenge 和 Serial Old 垃圾收集算法组合起来使用的情况比较少,并且在年轻代中使用并行算法,而在老年代中使用串行算法,这种并行、串行混搭使用的情况,本身已属罕见同时也很冒险。由于这两 GC 算法组合很少使用,却要花费巨大工作量来进行维护,所以在 Java 14 版本中,考虑将这两 GC 的组合弃用。
具体弃用情况如下,通过弃用组合参数:-XX:+UseParallelGC -XX:-UseParallelOldGC,来弃用年轻代、老年期中并行、串行混搭使用的情况;同时,对于单独使用参数:-XX:-UseParallelOldGC 的地方,也将显示该参数已被弃用的警告信息。
JDK15 - 禁用偏向锁定
准备禁用和废除偏向锁,在 JDK 15 中,默认情况下禁用偏向锁,并弃用所有相关的命令行选项。
在默认情况下禁用偏向锁定,并弃用所有相关命令行选项。目标是确定是否需要继续支持偏置锁定的 高维护成本 的遗留同步优化, HotSpot虚拟机使用该优化来减少非竞争锁定的开销。 尽管某些Java应用程序在禁用偏向锁后可能会出现性能下降,但偏向锁的性能提高通常不像以前那么明显。
该特性默认禁用了biased locking(-XX:+UseBiasedLocking),并且废弃了所有相关的命令行选型(BiasedLockingStartupDelay, BiasedLockingBulkRebiasThreshold, BiasedLockingBulkRevokeThreshold, BiasedLockingDecayTime, UseOptoBiasInlining, PrintBiasedLockingStatistics and PrintPreciseBiasedLockingStatistics)
JDK15 - 低暂停时间垃圾收集器
Shenandoah垃圾回收算法终于从实验特性转变为产品特性,这是一个从 JDK 12 引入的回收算法,该算法通过与正在运行的 Java 线程同时进行疏散工作来减少 GC 暂停时间。Shenandoah 的暂停时间与堆大小无关,无论堆栈是 200 MB 还是 200 GB,都具有相同的一致暂停时间。
怎么形容Shenandoah和ZGC的关系呢?异同点大概如下:
- 相同点:性能几乎可认为是相同的
- 不同点:ZGC是Oracle JDK的。而Shenandoah只存在于OpenJDK中,因此使用时需注意你的JDK版本
- 打开方式:使用
-XX:+UseShenandoahGC命令行参数打开。
Shenandoah在JDK12被作为experimental引入,在JDK15变为Production;之前需要通过-XX:+UnlockExperimentalVMOptions -XX:+UseShenandoahGC来启用,现在只需要-XX:+UseShenandoahGC即可启用
JDK16 - ZGC 并发线程处理
JEP 376 将 ZGC 线程栈处理从安全点转移到一个并发阶段,甚至在大堆上也允许在毫秒内暂停 GC 安全点。消除 ZGC 垃圾收集器中最后一个延迟源可以极大地提高应用程序的性能和效率。
JDK16 - 弹性元空间
此特性可将未使用的 HotSpot 类元数据(即元空间,metaspace)内存更快速地返回到操作系统,从而减少元空间的占用空间。具有大量类加载和卸载活动的应用程序可能会占用大量未使用的空间。新方案将元空间内存按较小的块分配,它将未使用的元空间内存返回给操作系统来提高弹性,从而提高应用程序性能并降低内存占用。
参考资料
《Java 全栈知识体系》Java 12 - 17 特性概述等文章
https://openjdk.java.net/projects/jdk/17/jeps-since-jdk-11
https://docs.oracle.com/en/java/javase/17/language/local-variable-type-inference.html